Ostrich
-
Gesamte Inhalte
25 -
Registriert seit
-
Letzter Besuch
Alle erstellten Inhalte von Ostrich
-
Netzwerkkonfiguration Hyper-V Cluster - CSV Geschwindigkeit
Ostrich antwortete auf ein Thema von Ostrich in: Virtualisierung
Danke @Nobbyaushb für den Tip. Ich bin schon mal ein ganzes Stück weiter und habe mir eine Testumgebung, mit 3 alten HP Proliant Gen8 (Xeon E5-2670), 256GB RAM, 2xNC530T Dualport 10Gbit Adaptern aufgebaut. Auf LBFO-Teaming habe ich schlussendlich verzichtet und das Ganze mit SET umgesetzt: #Abfrage der End-IP-Adresse des Systems $IP = Read-Host "Bitte geben Sie den vierten und letzten Bereich der IP-Adresse an (z.B. 101 fuer 192.168.210.101)" $IP1 = Read-Host "Bitte geben Sie den vierten und letzten Bereich der IP-Adresse (2. ISCSI-Adapter) an (z.B. 101 fuer 192.168.210.101)" # create switch New-VMSwitch -Name "vSwitch1" -NetAdapterName "LAN10G1","LAN10G3" -AllowManagementOS $false -EnableEmbeddedTeaming $true # Add Interface Add-VMNetworkAdapter -Switchname vswitch1 -Name Host -managementOS Add-VMNetworkAdapter -Switchname vswitch1 -Name CSV -managementOS Add-VMNetworkAdapter -Switchname vswitch1 -Name LiveMigration -managementOS Add-VMNetworkAdapter -Switchname vswitch1 -Name HeartBeat -managementOS Set-VMNetworkAdapterVlan -VMNetworkAdapterName "Host" -Access -VLANID 1 -ManagementOS Set-VMNetworkAdapterVlan -VMNetworkAdapterName "CSV" -Access -VLANID 91 -ManagementOS Set-VMNetworkAdapterVlan -VMNetworkAdapterName "LiveMigration" -Access -VLANID 92 -ManagementOS Set-VMNetworkAdapterVlan -VMNetworkAdapterName "HeartBeat" -Access -VLANID 93 -ManagementOS Anschließend VMQ und RSS konfiguriert - wobei ich mit beim RSS unsicher bin, ob das so bereits passt: # Configure VMQ set-netadaptervmq -Name "Lan10G1" -BaseProcessorNumber 2 -MaxProcessors 4 set-netadaptervmq -Name "Lan10G3" -BaseProcessorNumber 6 -MaxProcessors 4 # configure RSS Enable-NetAdapterRss * # network setting Set-NetadapterAdvancedProperty -Name "LAN10G1","LAN10G3" -registrykey "*JumboPacket" -registryvalue 9014 # Set-NetadapterRss -name "vethernet (Host)" -BaseProcessorGroup 1 -Maxprocessors 4 # Set-NetadapterRss -name "LAN10G2 iSCSI" -NumaNode 1 -BaseProcessorGroup 1 -baseProcessorNumber 2 -Maxprocessors 4 # Set-NetadapterRss -name "LAN10G4 iSCSI" -NumaNode 0 -BaseProcessorGroup 0 -baseProcessorNumber 2 -Maxprocessors 4 # IP Addresses # Assign static IP addresses to the virtual network adapters Set-NetIPInterface -InterfaceAlias "vEthernet (Livemigration)" -dhcp Disabled -verbose New-NetIPAddress -AddressFamily IPv4 -PrefixLength 24 -InterfaceAlias "vEthernet (Livemigration)" -IPAddress 192.168.1.$IP -verbose Set-NetAdapterBinding -Name "vEthernet (Livemigration)" -ComponentID ms_tcpip6 -Enabled $False set-dnsclient -InterfaceAlias "vethernet (Livemigration)" -RegisterThisConnectionsAddress $FALSE Set-NetIPInterface -InterfaceAlias "vEthernet (Heartbeat)" -dhcp Disabled -verbose New-NetIPAddress -AddressFamily IPv4 -PrefixLength 24 -InterfaceAlias "vEthernet (Heartbeat)" -IPAddress 192.168.0.$IP -verbose Set-NetAdapterBinding -Name "vEthernet (Heartbeat)" -ComponentID ms_tcpip6 -Enabled $False set-dnsclient -InterfaceAlias "vethernet (Heartbeat)" -RegisterThisConnectionsAddress $FALSE Set-NetIPInterface -InterfaceAlias "vEthernet (CSV)" -dhcp Disabled -verbose New-NetIPAddress -AddressFamily IPv4 -PrefixLength 24 -InterfaceAlias "vEthernet (CSV)" -IPAddress 192.168.2.$IP -verbose Set-NetAdapterBinding -Name "vEthernet (CSV)" -ComponentID ms_tcpip6 -Enabled $False set-dnsclient -InterfaceAlias "vethernet (CSV)" -RegisterThisConnectionsAddress $FALSE Set-NetIPInterface -InterfaceAlias "vEthernet (Host)" -dhcp Disabled -verbose New-NetIPAddress -AddressFamily IPv4 -PrefixLength 20 -InterfaceAlias "vEthernet (Host)" -IPAddress 10.65.140.$IP -DefaultGateway 10.65.139.1 -verbose Set-NetAdapterBinding -Name "vEthernet (HOST)" -ComponentID ms_tcpip6 -Enabled $False set-dnsclient -InterfaceAlias "vethernet (Host)" -RegisterThisConnectionsAddress $TRUE SET-DNSClientServerAddress -InterfaceAlias "vEthernet (Host)" -ServerAddresses 10.65.140.18,10.65.140.1,10.65.140.15 (Get-ClusterNetwork "CSV").Metric=900 Zum Schluss noch Netbios disabled: # Disable Netbios $adapters=(gwmi win32_networkadapterconfiguration ) Foreach ($adapter in $adapters){ Write-Host $adapter $adapter.settcpipnetbios(2) } Ein paar hier unwichtige Teile meines Scriptes (iSCSI_Konfiguration etc) hab ich erstmal weg gelassen. -
Netzwerkkonfiguration Hyper-V Cluster - CSV Geschwindigkeit
Ostrich antwortete auf ein Thema von Ostrich in: Virtualisierung
Hi Nils, ja das hab ich befürchtet. Hätte dennoch auf en paar Anregungen gehofft. -
Netzwerkkonfiguration Hyper-V Cluster - CSV Geschwindigkeit
Ostrich hat einem Thema erstellt in: Virtualisierung
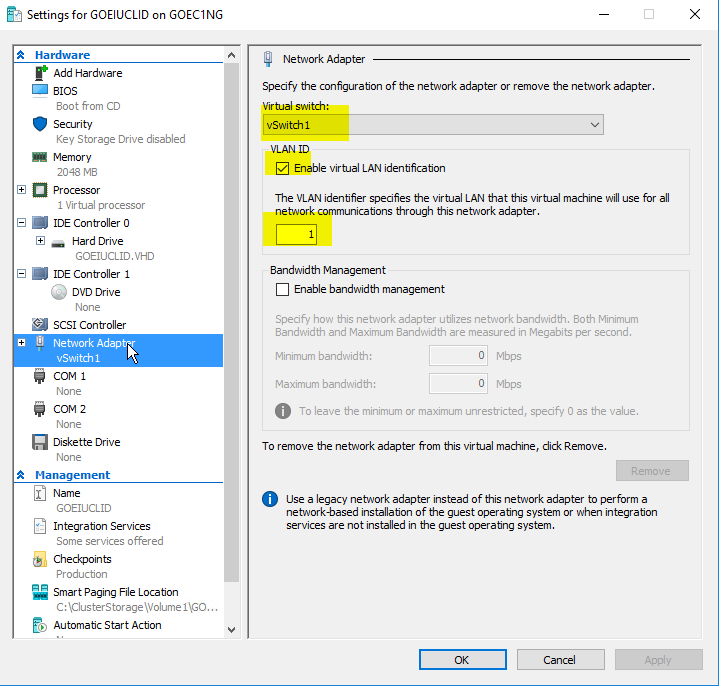
Hallo Zusammen, vielleicht kann mir hier jemand helfen - ich muss die Netzwerkkonfiguration eines HyperV-Clusters überarbeiten. ggw. sieht sie so aus: 3 Clusterkonten mit jeweils 4 NIC's 10GBit +1x1Gbit 2x10Gbit iSCSI-NIC an seperatem Switch 1x10GBit NIC für den Host (Cluster & Client) 10.65.128.0/20 VLan1 1x10GBit NIC für die VM's 1x1GBit NIC Heartbeat (Cluster only) 192.168.0.0/24 VLan Heartbreat Wir haben jetzt festgestellt, dass in dieser Konstellation das CSV deutlich ausgebremst wird, statt 700MB/Sekunde liegen hier maximal 40-200MB/Sekunde an. Als Ursache war nach einiger Recherche die CSV-Konfiguration festgestellt, da sie Folgendes nicht erfüllt: - geroutetes Netzwerk - kein eigenes VLAN Wie würdet ihr hier vorgehen? Mein erster Gedanke sieht wie folgt aus, in ANleitung an das hier Beschriebene: http://www.msserverpro.com/best-practices-setting-hyper-v-cluster-networks-windows-server-2016/ - 2x10Gbit als LACP Team aufbauen (passende Switche sind vorhanden) - Auf diesem Team die folgenden Netze anlegen: Management Cluster & Client Cluster Cluster only LiveMigration Cluster only Service Cluster only Folgende Fragen ergeben sich für mich: - Welcher Netze benötigen neben TCP/IP den MS-Client und SMB? Nur Management und Cluster, oder auch LiveMigration? - QoS - wie würde da eine Empfehlung aussehen? - VM-Netze: Macht es nicht Sinn, für jedes VLan, was den VM zugewiesen wird, einen eigenen HyperV-Switch anzulegen? Unsere VM's laufen im Wesentlichen in den Netzen "Produktion", "DMZ", "Management" und sind ggw so konfiguriert, dass Ihnen ein gemeinsamer HyperV-Switch zugewiesen ist, und in der Konfiguration eine VLAN-ID eingetragen ist (siehe Bild). Vielleicht hat auch jemand eine völlig andere Idee, bin für alles offen! Danke im voraus
-
moin moin, habe 1 HP Proliant DL380 G6 einen Windows Server 2008R2 mit SC DPM20120, 24 Agents, Shelf mit 20TB (externen via SAS-Controller) Storage für Recovery Points (Disk, 20 tage Vorhaltezeit) 1 Backup Library mit 2xLTO4-Tapes (Tape, 2 Jahre Vorhaltezeit) Aufgabe ist es, dieses Konstrukt in eine neue Hardware zu überführen und die alte Installation zu entsorgen, also nicht (länger) nebenher weiterzubetreiben. Ziel ist es, auch alte Recovery-Points (Tape) restoren zu können und die DB mit den historischen Recovery-Points zu behalten. Die Shelf mit den SAS-Controller und Disk's soll übernommen werden. Ich habe mit einem externen Dienstleister folgenden Vorschalg erarbeitet: - Installation WSRV2012+DPM2010 auf dem neuen Server Proliant DL380 Gen8 - Benennung und Konfiguration identisch zum alten Server! - SQL-Instanz und DPM2010-Konfiguration wird 1:1 übernommen (wie?) - Inplace-Upgrade auf DPM 2012 durchführen (Vorher: Aktuelles QFE-Rollup, DPMDB Um Berechtigung erweitern) - Später auf DPM 2012 SP1 migrieren, sobald verfügbar! - Agents updaten Kann das jemand so nachvollziehen oder gar bestätigen? Wo liegen die Schwachstellen bei dieser Vorgehensweise? Mein erster Gedanke war, mit einer völlig neuen Konfiguration zu starten, und die Alte Datenbank mit den Backup to TAPE-Recoverypoints irgendwie zu übernehmen. Danke!
-
2K8R2SP1 - Failover CLuster active/active/active
Ostrich antwortete auf ein Thema von Ostrich in: Virtualisierung
NorbertFe: Nein, nicht nutzlos, aber wie das 5. Rad am Wagen per Definition. @Dukel: klar, einen A/A Cluster würde ich je Node nur zu 40% belegen, einen A/A/A dann eben zu beispielsweise ca. 60%. Danke allen, die geantwortet haben! Ich denke, NorbertFE hat das Wort des Tages gesprochen: -
2K8R2SP1 - Failover CLuster active/active/active
Ostrich antwortete auf ein Thema von Ostrich in: Virtualisierung
Hi Nils, naja, wie Du meinst. Dann formuliere ich die eigentliche Frage mal anders: Ich habe vor, einen Hyper-V Failovercluster unter WSrv2008R2 mit 3 Nodes zu implementieren. - die 3 Nodes hängen an einem HP EVA SAN mit einem redundantem FC-Controller, es sind alle Windows-Updates, - alle Hardwaretreiber, alle AD-Konten, und alle Rollen auf den 3 Nodes sind identisch installiert, - der Cluster Validation zeigt alles grün. - "Node Majority" ist konfiguriert. - Der Clusterdienst ist in Betrieb, ein CSV ist implementiert und - die VM's sind den einzelnen Knoten zuweisbar. Verwendet werden soll für die "Migration" der vm vom alten Cluster auf den Neuen der VMM2008R2, aber dass ist ein anderes Thema! Zu den Begrifflichkeiten Host- und VM-CLustering: es ist mir bewusst, das eine VM immer nur auf einem Host läuft (aktiv/passiv), die Hosts selber sollen entweder a) A/A/A oder b) A/A/P laufen. In dem von Dir verlinktem Artikel heisst es nun aber, dass man "idealerweise" einen N+1 Cluster vorhält, der einen Node als passiven Node vorhält- In meinem Beispiel wäre das also mindestens ein passiver Node, also Variante b). Warum nicht Variante a) wo wenigstens nicht eine komplette Hardware komplett nutzlos dasteht, falls alles fehlerfrei in Betrieb ist? Ich hoffe, ich schaffe es nun, mich so auszudrücken, dass die Frage klar wird :). -
2K8R2SP1 - Failover CLuster active/active/active
Ostrich antwortete auf ein Thema von Ostrich in: Virtualisierung
Ups ... sicher? Hab ich mich so mies ausgedrückt, dass der Eindruck entstanden ist, dass mir die Grundlagen fehlen? Dann werd ich mal schwer in mich gehen ... schlage mich mit MS-Clustern seit 1999 und Hyper-V seit 2008 herum und dachte, die Grundlagen verstanden zu haben :confused:. @Dukel: ich rechne damit, dass etwas ausfällt, sonst brauch ich ja nichts zu (Failover-) Clustern ... Die Frage war nur @Lian: Den letzten Absatz hab ich gelesen und er hat meine These A/A/P untermauert, übrigens ist das die Konfiguration, in der mein jetziger Hyper-V Cluster läuft: @all: warum ist das "Idealerweise" so, war meine ursprüngliche Frage. Danke! -
2K8R2SP1 - Failover CLuster active/active/active
Ostrich antwortete auf ein Thema von Ostrich in: Virtualisierung
was trivialer ist? Nun, ich muss mir keine Gedanken um das Sizing machen, da immer eine komplette Hardware (der passive Node) frei ist, um die vm's von einen ausgefallenen Node zu übernehmen (ich will ja auch nur den Ausfall von 1 Node absichern). Sind die VM's auf 3 Nodes verteilt, wandern die vm's zu den verbliebenen 2 Nodes. Und genau das muss doch erstmal richtig konfiguriert werden, sonst steht irgendwann nicht genug RAM zur verfügung. Oder übersehe ich da was? -
2K8R2SP1 - Failover CLuster active/active/active
Ostrich antwortete auf ein Thema von Ostrich in: Virtualisierung
Danke für die Antworten! @Lian: Gesichtspunkte sind a) verfügbarkeit und b) sinnvolle Auslastung der Resourcen, genau in der Reihenfolge! Ist da aktiv/aktiv/passiv "sicherer" weil trivialer zu konfigurieren (es geht nur um Hyper-V). btw: Was meinst du mit dem Link auf "clustern von dc ..." hatte ich so nicht vor ... @NilsK: Danke für die links, hab ich mal was zum durcharbeiten. "Ziemlich" identische Hardware brauch ich doch aber spätestens für die Live-Migration der VM's .. @Dukel: ALso würdest Du auch aktiv/aktiv/aktiv vorschlagen, so dass sizing passt? -
2K8R2SP1 - Failover CLuster active/active/active
Ostrich antwortete auf ein Thema von Ostrich in: Virtualisierung
OH das sind aber gute Nachrichten! SO dümpelt nur "etwas" RAM nutzlos herum, während die CPU-Power mitgenutzt werden kann. btw: Neue Knoten müssen dann identische Hardware haben, oder? -
2K8R2SP1 - Failover CLuster active/active/active
Ostrich antwortete auf ein Thema von Ostrich in: Virtualisierung
Ups, ja klar gehts ausschliesslich um Hyper-V, Danke für den Hinweis! -
2K8R2SP1 - Failover CLuster active/active/active
Ostrich hat einem Thema erstellt in: Virtualisierung
Hallo Miteinander, ich planen einen neuen 3-Knoten Failover-CLuster für Hyper-V. Nun streiten mein Kollege und ich, obe es ein a) active-active-active oder ein b) active-active-passiv Modell wird. Für a) spräche die bessere CPU-Auslastung, da ja allen VM's mehr reale CPU-Kerne zur Verfügung stünden. Dem gegenüber steht die reichlich unklare Situation, wenn ein Node ausfällt, und die VM's auf die anderen beiden Nodes "verteilt" werden müssen, was die Konfiguration recht komplex macht - Oder? Ich habe von einem active-active-active Modell in der Praxis auch noch nie gehört! Für b) spräche die einfache Konfigration, da immer ein Clusternode Standby stünde, um für ausgefallene "Kollegen" einzuspringen. Ich habe gw. 15 Server mit 30 vCPU's und ca. 60GB Arbeitsspeicherbedarf zu verteilen auf 3x96GB RAM + 3x24 CPU-Kerne. Vielen Dank schon einmal! -
DPM 2010 Festplatte wechseln
Ostrich antwortete auf ein Thema von crazymetzel in: Windows Server Forum
Ich habs damit hinbekommen: Disk Migration (DPM 2007 w/ SP1) in Data Protection Manager Nach der Ausführung des scriptes geht im Hintegrund die eigentlöiche Migration los, kann man sehr schön in der DPM-Console beobachten! -
Hi, Also doppelte Sicherheit über die gesamte Storage-Group, da 2xHot Standby Danke Dir! btw: Sicher ist VMWare und vielleicht auch XEN eine momentan bessere Lösung. Schauen wir mal , was in ein paar Jahren ist, meine Virtual-Server/hyper-V Erfahrungen, speziell mit dem VM Manager aus dem Systemcenter, werd ich mal versuchen zu dokumentieren, geht jedenfalls bisher recht störungsfrei und problemlos, was MS da zusammengekauft und weiterentwickelt hat! Momentan stehen jedenfalls 3x3T€ für die Wsrv2008 Datacenter-Edition 24T€ für 40 Standradserver gegenüber, was sich auch in einem VL Enterprise Vertrag entsprechend wiederspiegelt. Ausserdem: Hyper-V ist für kleine Standorte wie geschaffen, wo "mal eben" ein proxy oder ein kleiner Anwendungsserver auf "dem" physikalischen Windows-Server mitlaufen soll. Ich bin hier rundum-verantwortlich für 110 Server in 13 Standorten, da möchte ich schon entsprechend sinnvoll ausdünnen können.
-
Mensch leute, ihr gebts mir aber richtig :-( ich komm mir ja so was von disqualifiziert in dieser Expertenrunde hier vor, das glaubt ihr gar nicht! Aber der Reihe nach: @thorsatten: - vraid: 24x400GB FC HDD, davon 2 HSB Die HSB werden nach meinem Verständniss automatisch verwendet, wenn eine der anderen 22 Platten ausfällt. Alle LUN's erstrecken sich über alle Platten (vraid). Wodurch unterscheidet sich denn einfache von doppelter Ausfallsicherheit? - das mit den 2 HBA's je Node werde ich vorschlagen, Argumentation passt soweit, es muss halt alles irgendwie auch ins Budget passen ... - 400GB 10k Disks in "grossen" Storagegroups performen ausreichend schnell, wobei gross wohl Definitionssache ist. 24 Platten sind eher klein. I/O-last war dennoch bisher kein thema, wird aber sicher noch mal Thema werden! Danke Dir, Thorsten, aber schonmal sehr! @phoenixcp: 1) über die gesamte Storagegroup (24x400GB) 2) Wir hatten in den Werken (6 Werke, 4 in Europa+2 in Asien),sonst FT-Server von stratus, welche in Hardware ausfallsicher sind. Stimmt! Weist du was ausgefallen ist? - der Plattenplatz ist ausgegangen (Softwarefehler) - der Strom ist länger ausgefallen, als die APC und der nachgeschaltete Diesel Notbetrie aufrecht erhalten konnten - 2x ist ein Cisco Switch defekt gegangen Ich will versuchen, das Restrisiko über ein "startfähiges Image" (um snapshot nicht wieder zu bemühen ..) des SQL-Servers im WOrst-case Szenario abzufangen. 3) Siehe Kommentar an Thorsten, wird verargumentiert + Entscheidung dahingehend abgeändert. Danke auch Dir! @all: keiner mehr nen Kommentar zum Hyper-V Cluster, nur zum SAN?
-
Guten Morgen zusammen, und erstmal bin ich überwältigt von den vielen. sehr qualifizierten und ausführlichen Antworten, ganz speiell an NilsK! Natürlich wird nicht komplett virtualisiert, 2 DC'S, 2 Exchange, 1-2 Filer und noch eine handvoll weiterer Server werden nicht Bestandteil des Clusters. es geht also, abgesehen von 1-2 SQL-Servern und 1 Oracle um Server, die hochverfügbar sein müssen, aber keine nenenswerte I/O oder CPU-Last haben. Server, die vor kurzem noch auf einem BNC-Netz und einem Pentium Pro mit 128MB gelaufen sind ... dort ist schon im Vorfeld mächtig ausgesiebt worden! Zudem: Kunde hat 12-15 Server (oder besser: Installatationen!) auf einem Virtual Server 2005 R2 (1 Dualcore Opteron, 16GB RAM, davon 5 GB frei, CPU-last: 5-35%, Peak 50%), der mit gehostet werden soll. Das Thema Last würde ich hier zunächst mal abschliessen, kommen wir zum Konzept: RAID5 doer RAID1: in dem EVA-SAN kommen (neben einem 4Stunden Wartungsvertrag bei Ausfall von Platten) 2 Hot-Standby Platten zum Einsatz, die beim Ausfall einzelner Platten dann einspringen. Alerting ist konfiguriert. Raid-Level ist daher aus meiner Sicht daher nur für I/O wichtig, RAID1 erzielt eben 30% bessere IO's, wenn man HP da glauben darf. Clusternode: 2 Server produktiv, 1 Server hsb bedeutet ja nicht, dass der hsb beide ausgefallene nodes ersetzen kann, sondern nur einen. auch hier: Wartungsvertrag, reaktion bis next business day, das sollte nach meinem ermessen reichen! UND: bei komplettausfall des SANs sollen die produktionswichtigen VM's auf einem externen Array liegen (iSCSI, räumlich getrennt), und manuell anstartbar sein. Es geht hier um wirkliche PRODUKTION und nicht darum, Lieferscheine zu drucken oder eine mailsystem PRODUKTIv zu halten, da rollen ganz einfach Steine vom Band, ohne den Server steht das BAnd eben :-) Damit zusamenhängend: Thema Snapshot: Klar, ein Snapshot allein reicht nicht! Daher sollen die VHD's und die Konfig+Snapshot-verzeichniss zyklisch nach extern (iscsi?) wegkopiert werden. Spricht da etwas dagegen? Thema 2. HBA: Fällt der HBA aus, fällt der Clusternode aus, das ist klar! Am nächsten tag kommt der HP-techniker und tauscht den HBA, dann geht der Clusternode wieder produktiv. Wo liegt dennder benefit, oder, welches Risiko umgehe ich mit 2 HBA's? mein HBA hängt an einem FC-Switch, an dem 2 Controller für das SAN mit dran hängen. macht man es konsequent, braucht man 2 Switche, und hängt dann an jeden einen Controller, und bindet an jeden Switch ein seperates HBA an. Aber, wer soll das bezahlen? Der Mittelstand sicher nicht ... für die ist ein FC-SAN schon eine Hammerinvestition gewesen! Daher, auch hier, ein Kompromiss.
-
moin moin, heute früh der Sprung ins kalte Wasser ... neues projekt, frage nach Realisierbarkeit: Kunde möchte 40 Server virtualisieren, überwiegend Anwendungsserver irgendeiner betriebswirtschaftlichen Software, aber auch 1 SQl-Server und 1 Oracle 10. Oberster gesichtspunkt, wie so häufig, Kosteneinsparung, daher fiel aus litzenzrechtlichen gründen auch die Wahl auf Hyper-V (klar, 3 datacenter Lizenzen sind günstiger als 40 standard-server) zweiter Aspekt, verfügbarkeit: Es soll ein failover-Cluster realisiert werden dritter Aspekt: Wiederherstellbarkeit: Nach einem Ausfall oder einem missluingenem Update soll einfah das letzte Snapshot zurückgespielt werden. Infrastruktur: - Es werden 3 Server DL385 R05P bereitgestellt, jeder hat 2 Quad-CPU's, 64GB RAM, 4 LAN-Interfaces + 1 ILO, dazu 2x150GB lokale Festplatte zum booten. Weiterhin: 1 HBA zur verbindung mit dem SAN - Das SAN selbst ist neu angescha´fft worden, eine EVA 4400 mit 24x400GB, wovon 3TB schonmal für file/mailserver draufgegangen sind (alles raid5). Der Rest stünde für die VM'S zur verfügung. Ich hab nmir nun Folgendes gedacht: - 2 Datacenter Server als Core installieren mit hyper-V+Clusterrolle - 1 Datacenter Server "Standard" mit hyper-V+Clusterrolle als Hot-Standby + zur verwalötung dazu gestellt - 2 LUN's im SAn mit dem Cluster verheratet: 1 für die vm's selbst (Raid5) und eine für datenintensive vhd's (Raid1). Grösse: 1TB RAid5 und 0,5TB RAID1. - Übername der 15 vorhandenen VM'S (Vitual Server 2005 R2) auf den Cluster - VM's werden auf die Clusternodes (also am Ende die physikalischen hypervisor) nach Funktionen verteilt, also typischerweise einer für alle kafmännischen, einer für alle technischen, und der dritte als "failover" zum abfangen des ausfalls einer der beiden hypervisor Seht ihr vom konzept her Verbesserungsbedarf? habt ihr ähnliches schon umsetzne dürfen, und wenn, wie waren die Erfahrungen, was waren die Stolpersteine, die man vermeiden kann? Vieleicht klingt 40 Server auch einfach zu dramatisch, es sind überwiegend unbelastete server, die teilweise nur lizenen vorhalten+ausspucken, managementsoftware für irgendwas (cisco, watchguard, HP SIM usw) beinhalten und ansonsten 24 Stunden am tag idlen. Die einzigen Kracher sind der/die SQL- und Oracle-Server. Hoffe auf gute Antworten+üwerde das projekt auch mal hier vorstellen, so es gelingt! gruß harald
-
W2000 / Exchange 2000 nach SBS 2003 R2 mirgrieren
Ostrich hat einem Thema erstellt in: MS Exchange Forum
Moin zusammen, eine bestehende W2K/W2003 Domäne mit einem Exchange 2000 sollte migtriert werden nach SBS 2003 R2. Step 1, also Integration des DC vom SBS mit anschliessendem Übertrag der Rollen lief recht problemlos. Also weiterinstalliert, nun war der Exchange Server dran. Leider war die bestehende Domäne eine Deutsche, der SBS aber nun ein englischer. Folge: Exchange kennt nun 2 Administratibe Gruppen, nämlich die "erste Administrative Gruppe" und "first administrative group" Soweit-so schlecht! Eigentlich wollte ich ja nun nicht nur die Postfächer rüberschieben (das funzt auch), die Konnektoren einrichten (die laufen schon) und die public folders rüberholen. Hatte mir extra das letzte pfmigrate gezogen und voler Tatendrang angefangen. Leider findet findet pfmigrate nicht einen einizigen Ordner! Nun meine Frage: - kann ich während der Installation beeinflussen, in welcher administrativen gruppe ein Server landet? - kann ich die "first administrative group" noch einmal richtig "platt machen", um den exchanger dann in die andere zu verpflanzen? - einfacher: kann ich die pub1.edb nicht irgendwie einfach importieren? Es wäre organisatorisch überhaupt kein Problem, alle User/Postfächer alle auf einmal rüber zu ziehen und in einem einzigen "harten" Schritt die gesamte Organisation auf den SBS 2003 umzustellen. BTW: Weiß jemand, wie ich die Sharepoint-Portalservices im nachhinein instalieren kann? Habe inen Eintrag im Syslog, das die Sharepoint Time Services wegen eines Authentifizierungsproblems nicht starten (Account des Dienstes: netzwerK) Niemand eine Idee? Danke schonmal! -
SBS 2003 R2 Premium und Lizensierung
Ostrich antwortete auf ein Thema von Ostrich in: Microsoft Lizenzen
Guten Morgen die Herren, und vielen Dank für die Antworten, das Spekulieren über die Konsequenzen werde ich dann mal hier lieber lassen. Also werde ich den Lizensierungsdienst im SBS einfach laufen lassen und nicht mehr anschauen, vielleicht bin ich eben etwas paranoid in der Frage, seit mir einmal unversehens vor Jahren ein paar TS-CAL's in einem extrem ungünstigem Moment "ausgefallen" sind. -
Hallo Miteinader, ein frisch installierter SBS2003 bereitet mir Probleme, aber der reihe nach: - in einer bestehende Domäne wurde ein sbs2003 r2 installiert (nach anleitung, also manuelles dcpromo, rollen übertragen,. lizensierung übertragen). So weit-so gut! In der Domäne stehen weiterhin ein alter W2K und ein recht neuer W2K3-DC, die beide demnächst abgeschalten (also dcpromo zum memberserver, und danach auch aus domäne entfernt) werden sollen. - Während er installation des SBS2003R2 Premium wurde ich NICHT nach der Art der CAL gefragt. Irgendwo in den Lizenpapieren des Kunden stand, dass der Server 25CAL enthält. - Rufe ich nun auf dem Server die Lizensierung auf, so werden mir 5 integrierte CAL angezeigt. Es werden mir keine verwendungsart (user/Device) oder weiter produkte (Windows Server, Exchange-Server, SQL-Server ...) angezeigt, obwohl diese auf dem W2K-DC eingetragen sind (und dort auch unter dem Lizenzüberwachungsdienst aufgelistet werden) -> Wozu habe ich im AD-Sites und Services-License-Server dann überhaupt den SBS eintragen müssen? Was passiert mit den Lizenezen, wenn der W2K-DC entfällt? - Die jediglich 5 integrierten CAL sind für mich das grössere Problem. Ich habe hier im Forum gefunden, dass bei User-CAL 5 biologische User gemeint sind., nicht 5 Benutzerkonten. Kann ich also davon ausgehen, dass der Lizensierungsdienst hier a) USER-Cals verwnedet und b) diese nicht anhand von Anmeldungen oder Anmeldenamen, sondern von biologischen Usern zu zählen versucht-was natürlich nicht möglich ist. Im Endeffekt würde das bedeuten, dass ich beliebig viele Userkonnten mit dem SBS verbinden kann, ohne auf eine technische Barriere zu stossen ... sehr sehr eigenartig! Was meint Ihr? vielen Dank schonmal im Voraus! Harald
-
Software Raid-1 - als zusätzliche SIcherheit empfehlenswert?
Ostrich antwortete auf ein Thema von Ostrich in: Windows Server Forum
Gebe Dir ja prinzipiell recht, nur ist das SAN eine politische, keine technische Entscheidung. Das 2 Platten gleichzeitig abrauchen habe ich bei meinen ca. 400 Servern auch noch nie erlebt, aber das sie innerhalb von ein paar Stunden nacheinader abrauchen schon einige male, und wenn mir dann das Zeitfenster für einen Restore ausgeht (ich produziere mit meiner Farm 24/365) möchte ich eben mit Hilfe des Software-raid weiter produzieren können. -
hi, wozu wins? dcpromo reicht eigentlich, das instet nen dns-server (ad integrierte zone) auf anforderung mit.
-
Software Raid-1 - als zusätzliche SIcherheit empfehlenswert?
Ostrich antwortete auf ein Thema von Ostrich in: Windows Server Forum
so ein wenig ... SAN ist natürlich auch Raid(5 denke ich) und lokal 5 platten wären dann auch raid (ebenfalls 5). Mein Gedanke ist, wenn nun zbsp. am SAN mehr als 1 platte ausfällt, steht dem Server immer noch der lokale Raid(5)-Array zur verfügung, und beide sind als raid1 miteinander verbunden. also: hardware raid(5)+hardware raid(5) als software raid(1) verbunden. Dass ein raid kein backup ersetzt ist mir schon bewusst, was mich ein wenig irrirtierte waren die fehlfunktionen beim restore :-( aber das ist eine gaaanz andere baustelle! -
Software Raid-1 - als zusätzliche SIcherheit empfehlenswert?
Ostrich antwortete auf ein Thema von Ostrich in: Windows Server Forum
Das SAN fällt überwiegend dann aus, wenn Hardwarekomponenten über den Zenit sind, meist sind es Plattenausfälle, welche den Ausfall ganzer Trays nach sich ziehen. Zudem lässt der Support stark nachg, wenn eine Firma (storagetek) von einer anderen (Sun) aufgekauft wird, die nun ihrerseits eigene Produkte zu etablieren versucht. -
Software Raid-1 - als zusätzliche SIcherheit empfehlenswert?
Ostrich hat einem Thema erstellt in: Windows Server Forum
Hallo, ich plane mit einem recht kleinen Budget (6T€) einen neuen Exchange-Server. Basis soll ein HP proliant DL380G5 werden (Xeon 3.0ghz, 3GB RAM, 7x70GB Festplatte ...) sowie einem hba mit Anschluss an ein SAN-System. Sow eit-So gut - nun kam es aber in letzter Zeit zu häufigen Ausfallzeiten am SAN-System, dessen Wartung wird immer teurer und es soll wohl in den ächsten Jahren einmal abgelöst werden. Aber nicht 2007-vieleicht noch nicht mal 2008! Um nun ein gewisses Maß an Ausfallsicherheit zu gewährleisten habe ich mir folgendes überlegt: - 5x70GB Platten werden zu einem hardware-Raid5 zusammengeschlossen (280GB) - 280GB ist auch der Platz auf dem SAN-System, der mir zu Verfügung steht. - beide "Platten" werden als Dynamische datenträger eingebunden und per SOftware zu "einem " Raid-1 (spiegelung) zusammengeschlossen. Was haltet ihr davon? Ich weiss selbst, dass bei Hochverfügbarkeit ein Clustersystem und ein zweites SAN (wegen gemeinsamen Datastore) nötig sind, jedoch stehen mir´diese Resourcen momentan nicht zur verfügung :(