Weingeist
-
Gesamte Inhalte
1.627 -
Registriert seit
-
Letzter Besuch
Alle erstellten Inhalte von Weingeist
-
Storage Spaces Direct Volumes für iSCSI Target verwenden
Weingeist antwortete auf ein Thema von KorF in: Windows Server Forum
Habe ja doch einige Storage-Spaces Konstrukte im Einsatz und mittlerweile ~10 Jahre Erfahrung damit. Allerdings verwende ich für die Anbindung an VmWare NFS und nicht iSCSI. Machbar ist es auch mit iSCSI, nur hängt man mit iSCSI noch einen Layer Komplexität mit drauf weil nicht nur die MS-Systeme ein Filesystem unterhalten müssen, sondern auch VmWare. Je nach den Zielen die man verfolgt ist das kontraproduktiv. Bei Hyperconverged bringt es defintiv mehr Gefahr als Nutzen. Anbei aber mal die Antwort auf deine Frage: https://www.informaticar.net/create-two-node-storage-spaces-direct-s2d-in-hyper-v/ https://www.informaticar.net/create-iscsi-target-cluster-on-windows-server-2019/ https://www.informaticar.net/server-basics-11-create-shared-storage-in-windows-server-iscsi-target/ Die Frage ist halt wirklich, was man zu welchem Preis erreichen will. Preis jetzt nicht nur im Sinne der Kosten, sondern auch der Betriebs-Sicherheit. Da ich möglichst viel Komplexität vermeiden und die Dinge so einfach wie möglich halten möchte, verwende ich daher entweder eine SAN oder verzichte auf Host-Redundanz beim Speicher und somit die Cluster. MS als Hostspeicher würde ich dann erst wieder in Betracht ziehen, wenn man die doch relativ hohen Anforderungen erfüllen kann/möchte. Das wird dann aber kaum günstiger als eine SAN, dafür aber möglicherweise flexibler. Ist aber nicht mehr meine Welt. ;) -
Tool um benötigte Ports von Anwendungen zu ermitteln
Weingeist antwortete auf ein Thema von donnervogel515 in: Windows Forum — LAN & WAN
Die mitunter etwas aufwendige aber ebenfalls wirkungsvolle Methode ist das Auditing der Windows-Firewall/BFE einzuschalten und die Sicherheitsevents entsprechend auszuwerten. Oft ist es am einfachsten, wenn man einfach mal die Kommunikation blockiert, die Verbindungsversuche auswertet und dann nach und nach freigibt was notwendig ist und wieder schaut was blockiert wird oder welche Funktion nicht funktioniert etc. So erkennt man auch gut, ob Alternativmethoden, IP-Adressen etc. angefragt werden. Ist halt auch gut Handarbeit dabei, dafür bekommt man es auch recht granular raus bzw. kann ein Verhalten je nach dem auch provozieren. -
Wie automatisiert man das Windows10-Deployment vom USB-Stick? incl. Datenschutzeinstellungen
Weingeist antwortete auf ein Thema von q617 in: Windows 10 Forum
Man kann die entsprechenden Policies (gpedit.msc) und/oder Regwerte auch mittels Script einpflanzen. Wenn einem das Deployment-Toolkit zu oversized ist. Die Fragerei wird man mit einer unattended.xml los. (Etwas suchen) -
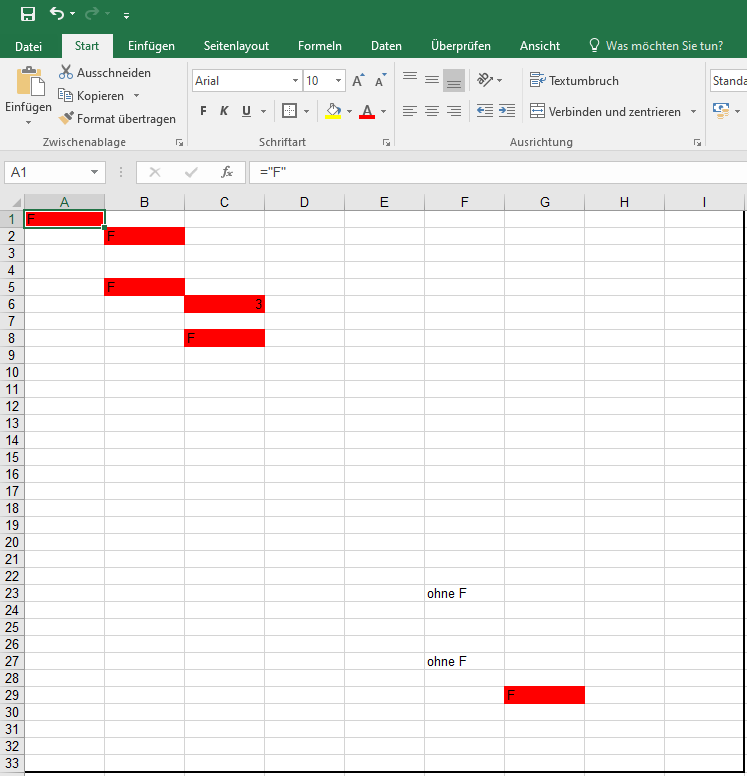
MS Excel Formel Zelle farblich markieren
Weingeist antwortete auf ein Thema von BSChris in: Windows Forum — Allgemein
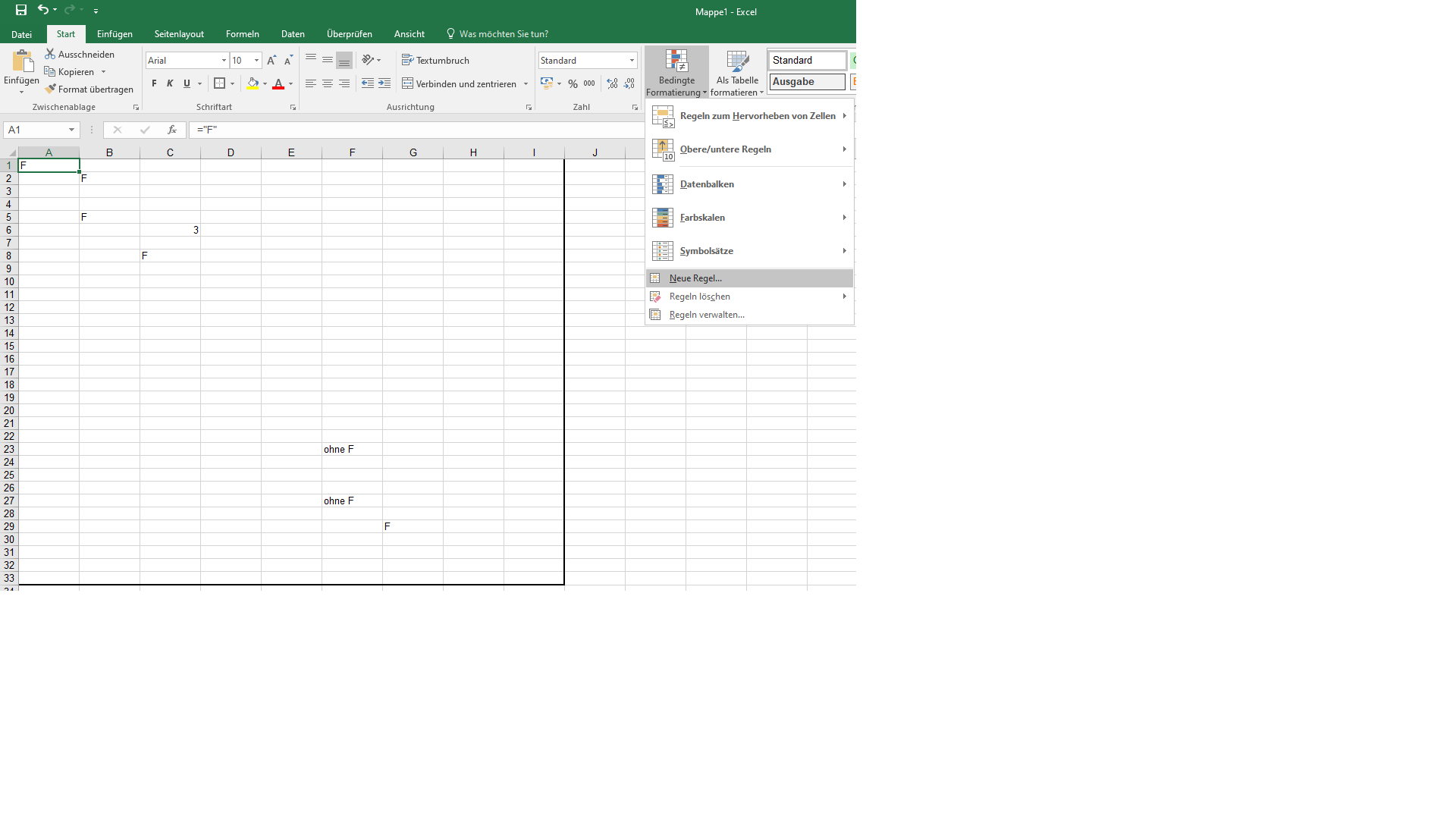
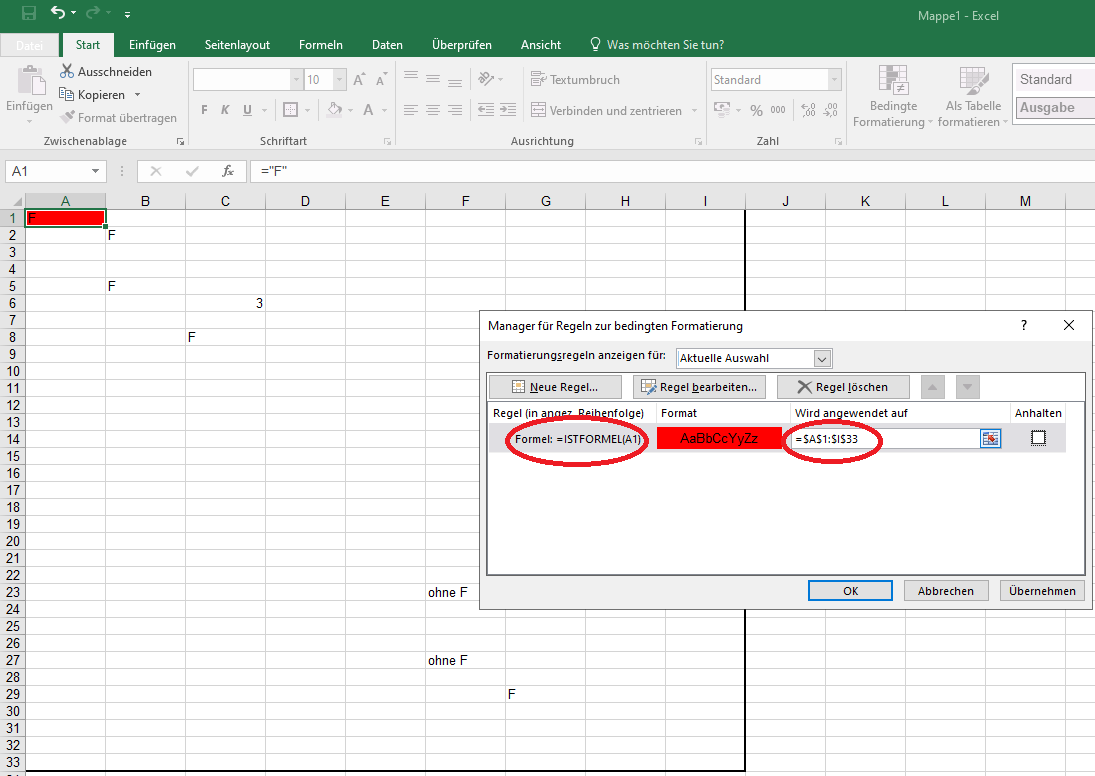
Woran scheiterst Du? Im Anhang eine kleine Fotostory. Im V5 siehst das Ergebnis. ohne Formel enhält zwar text aber keine Formel. Die anderen Texte (F) sind mit ="F" eingegeben.
-
MS Excel Formel Zelle farblich markieren
Weingeist antwortete auf ein Thema von BSChris in: Windows Forum — Allgemein
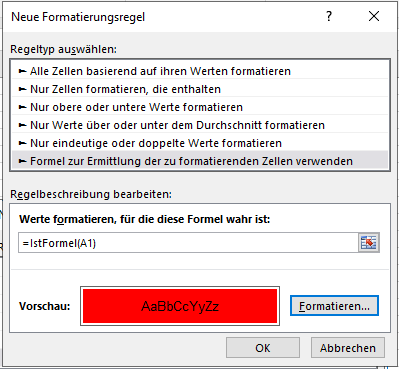
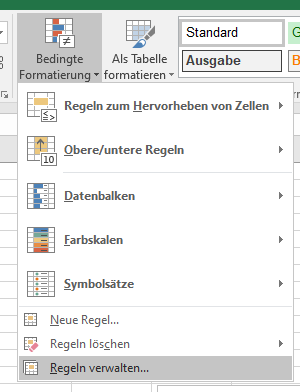
Also entweder IstLeer oder IstFormel sollte funktionieren. Bei der bedingten Formel eine "Formel" eingeben. Dazu die linke obere Zelle des Feldes angeben. Also z.Bsp erstellst für A1 eine bedingt Formatierung. Als Methode gibst Du bei "Formel zur Ermittlung ...." die Funktion ein. =IstFormel(A1) nicht IstFormel($A$1) wie es Excel standardmässig macht. Danach ziehst das Feld A1 einfach weiter oder erweiterst den Formelbereich bei wird angewendet auf den gewünschten Bereich. Dann können die Formeln auch vorher schon dastehen. ;) -
NTLM raubt mir den Nerv bzw. deren Ausnahmen
Weingeist antwortete auf ein Thema von Weingeist in: Windows Forum — Security
Mal ein Update wo ich noch Hilfe bräuchte: Aktuell kämpfe ich immer noch damit, dass der User-Manager Service via seiner svchost.exe in gesperrtem Zustand des Computers (User angemeldet, aber nicht am Platz), irgendwas mit NTLM authentifizieren möchte. In der Regel dauert es ein paar Stunden nach dem sperren. Anschliessend gibts folgende Sympthome: Anwendung der User Polices schlagen fehl (Computer scheinen zu ziehen, bin aber nicht 100% sicher, da schwierig zu prüfen) SMB-Verbindungen werden getrennt Es kommt beim Anmelden eine Info, dass die aktuellen Anmeldeinfos nicht aktuell sind und man sich an- und abmelden soll. Diese verschwindet aber rasch wieder. Meldet man sich wieder an, werden alle Verbindungen wieder mit Kerberos aufgebaut (Tokens werden wieder ausgestellt, nachprüfbar im Log). Das wäre nicht ultra-dramatisch, wenn ich nicht ein paar Anwendungen hätte, denen die Trennung gar nicht schmeckt. Braucht jedes mal ein Restart der Anwendung. Die alten Reg-Flags die das trennen verhindern, scheinen nicht mehr zu ziehen. Im Printerbereich/Scanner hoffe ich, dass Canon endlich nachzieht. Dann könnte ich ein paar Workarounds aufheben. Meine Anfragen werden immer mit dem Verweis auf die Sicherheitsangaben im Manual für SMB verwiesen. Jemand "Grösseres" mit mehr Einfluss hier oder anderen Infos? Laut meinem Distri bin ich immer noch der einzige der das überhaupt nachfragt und sie erhalten keine bessere Antwort von Canon als ich selbst. Kann ja eigentlich nicht sein. Kommt dann vielleicht wenn das enforcment erzwungend wird... Dann ein kleines Update zum Workaround den ich nun seit mehreren Monaten im produktiven Einsatz habe: DFSR-Variante zwecks Sync und reine Bordmittel. eigenes LAN für Maschinen mit NTLM und Lanport auf Relay wo möglich und die Kommunikation des Relay mittels Firewall auf die NTLM-Clients eingeschränkt. Alles an sonstigen Massnahmen aktiviert, was geht (Erst alles aktiviert, dann einzeln deaktiviert um herauszufinden was notwendig für die Funktion war) NTLM in der ganzen Domäne Deaktiviert und enforcement auf den DC's auf 2, für die OU mit dem Relay-Server NTLM Beschränkung aufgehoben. *1) Freigegebener Ordner auf dem Relay-Server in welchen die Maschinen (z.Bsp. Scanner) mit einem Service Account und NTLM-Auth schreiben dürfen DFSR welches diesen Ordner mit einem Ordner auf einem Filer synchronisiert der wiederum zugänglich ist Das Service-Konto für den SMB-Verkehr darf sich jeweils weder per RDP (eh gesperrt) noch lokal anmelden. Besitzt Lese/Schreibrechte für den Ordner. Für lokales Anmelden gibt es einen speziellen Admin Account für diese Maschine in der Domäne. Ansonsten hat er keine Rechte. Da mein Wissen eher breit als besonders tief ist in den einzelnen Gebieten, würde mich die Meinung von ein paar Profis interessieren, inwiefern solche Massnahmen ausreichenden Schutz bieten oder ob das nur Aufwand für wenig Schutz ist. 1*) Da nur der Relay-Server NTLM akzeptiert, schlagen alle Authentifizierungsversuche gegen Domain-Accounts fehl wenn sie mit NTLM getätigt werden. Man kann leider nach wie vor keine Remotemaschinen-Ausnahme definieren wenn SMB-Signing aktiviert wird. Daran haben auch die aktuellsten April-Updats nichts geändert (Server-Account und nicht der Initiator - also z.Bsp. der Scanner - wird gelogt). Das macht die Auwertung mühsam. Wer weiss Abhilfe? Leider hat dieser Workaround wohl ein Ablaufdatum, weil MS die Möglichkeit von Ausnahmen voraussichtlich im Oktober/November entfernen wird. Ich schätze der Termin wird verlängert, aber selbst wenn er nur mit Remote-Ausnahmen möglich bleiben würde, bringt das eigentlich nichts, weil er die Remote-Maschine nicht als solche behandelt. Der zweite Workaround mit der komplexeren Shared-Disc-Aktivierung-Deaktiverungs-Geschichte via zwei VM's ist je nach Art der Kommunikation (Einweg oder Zweiweg) einigermassen umständlich, wende ich aber nach wie vor an wo ich ein LAN-technisch strikte Trennung haben möchte. Aufgabenplanung mit Scripts für das Aktivieren/Deaktivieren der Disc um die MFT neu zu laden um zu erkennen ob die andere VM etwas geschrieben hat (sonst sind die Files nicht sichtbar) --> Gibts dafür auch nen einfcheren Weg wie nen WMI Befehl? Indexdienste auf die HDD deaktivieren um MFT-Beschädigung zu vermeiden Lockfile dessen anwesenheit man abfragt und verhindert das der Partner schreibt wenn er es gerade tut (wenn Zweiweg notwendig ist, ist aber trivialer wenn man mit zwei Festplatten arbeitet. Für jede "Schreibrichtung" eine. Alles halt recht hässliche Work-Arounds, weil die Industrieumgebungen leider nicht so schön aktuell zu halten sind wie die Büros, aber heute alles vernetzt sein muss. -
Best practice - Windows setup am Fliessband im Unternehmen
Weingeist antwortete auf ein Thema von codeslayer in: Windows Forum — Allgemein
Mir wurden die ständigen Änderungen irgendwann zuwieder. Ständig ging irgendwas des Deployments nicht mehr, was vorher ging. Heute habe ich ein umfangreiches Powershell-Script bzw. ein Basis-Script mit den gewünschten Parameter/Einstellungen welches auf dem Maschine verbleibt (habe eh wenige 0815 Maschinen) und wenn ich nen Wartungsstick/Discs (Bei VM's) von mir einstecke/verbinde, lädt es bei Ausführung die entsprechenden Funktionen nach. Manchmal brauchts einfach ein Upgrade des Parameter-Scripts wenn man neue Funktionen auf alten Installationen möchte. Das Script erstellt dann z.Bsp. Basic Firewall-Ruleset, deaktiviert Dienste, Aufgaben, konfiguriert Pagefile, IP-Dienste, evtl. fixe IP-Adressen, installiert gewählte 0815 Software, aktiviert dieses mit den entsprechenden Keys usw. je nach Art des Clients oder Servers den ich aufsetzen möchte. Den Rest erledigen dann die GPO's der jeweiligen Umgebung. Das ist insgesamt recht effinzient. Ein Script hat den Vorteil, dass es mit jeder neuen Idee welche MS grad hat, die Anpassungen trotzdem einfach funktionieren, weil MS die Rückwärtskompatibilität von Script-Code enorm hoch hält. Im Gegensatz zu den Deploymenttools (keine Ahnung wie das heute ist, habe seit ~10 Jahren keine Erfahrung mehr damit). Bis auf wenige Ausnahmen die man z.Bsp. Build-abhängig macht. Das Script läuft dann für XP oder W11 durch. Die neuen Befehle schreibe ich meist als Kommentar hin ab wann es geht. Wenn dann wirklich das letzte System von XP/7 in Rente ist (Juhui, mein letztes W95 ging vor kurzem in Rente), kommen dann die neuen Befehle rein. Oder wenn der alte Weg instabil ist (wie Netzwerkadapter mutieren) wirds ganz weggelassen bei unter Min-Version und nachgearbeitet. ;) Mir hat es das leben jedenfalls um ein vielfaches einfacher gemacht und habe es nie bereut von den Deployment-Tools auf Script zu wechseln. In grösseren Umgebungen wo dann wieder einzelne Leute oder gar Gruppen für das Rollout zuständig sind und auch viele exakt identische Maschinen auszurollen sind, macht es aber vermutlich wieder mehr Sinn mit den Veröffentlichtungstools zu arbeiten. Da ist dann das Verhältnis von ausgerollten Maschinen zum Anpassungsaufwand einer neuen Windows-Version nicht mehr so übel wie in kleineren Umgebungen. -
Probleme mit Registry Eintrag "Prefer IPv4 over IPv6"
Weingeist antwortete auf ein Thema von winmadness in: Windows 10 Forum
Ist halt die Frage ob man die Tunnel wirklich zulassen möchte oder ob man nicht besser auf Sie verzichtet. Sicherheitstechnisch ist die Technik zumindest etwas fragwürdig (EDIT: Zumindest war sie es, ob das heute noch gilt, weiss ich ehrlich gesagt nicht). Schiessen ja eigentlich ein Loch durch die Firewall. Klar bei Standardkonfig spielt das nicht so eine Rolle, gehört man aber zu jenen die tatsächlich die Firewall anpassen und sonstige Massnahmen technisch, wird es undurchsichtig mit den Tunnels. Wie viel das tatsächlich ausmacht, kann ich nicht so gut beurteilen, aber hilfreich ist es kaum. Am Ende muss man Firewall-seitig aber drei Techniken im Auge haben statt eine oder zwei. Hat man Probleme wie Dein geschildertes Verhalten mit den Verzögerungen und ist diese App auf dem Laptop Standard, müsste man korrekterweise Windows zwingen, erst IPv4 zu verwenden und IPv6 nur, wenn IPv4 nicht vorhanden ist. Also das Standardverhalten umdrehen. Das ereicht man indem man die Priorität in der Prefix-Policy von IPv4 gegenüber IPv6 erhöht. Insbesondere vom Loopback. Ich persönlich fände das sauberer als IPv4 einfach durch den IPv6 Tunnel zu schicken. IPv6 wird dadurch nicht verhindert, sondern es wird einfach erst IPv4 versurcht. Dazu müsste man die Prefixpolicy anpassen. Möchte man die Tunnels loswerden und nur IPv4 und/oder IPv6 nativ zu verwenden, ist meine Erfahrung, dass es in heterogen Umgebungen schmerzfreier ist, IPv4 die höhere Priorität einzuräumen. Entweder mit deaktiviertem IPv6 oder eben aktiviert. Dazu muss man die Prefixpolicy anpassen. -
USN-Rollback 2 DCs, beide laufen, einer wurde (leider & unnötig) restored, wie vorgehen
Weingeist antwortete auf ein Thema von cartman14 in: Active Directory Forum
Nur der Vollständigkeit halber, Computerkennwörter kann man doch neu setzen. Dürfte dann auch ohne Join funktionieren oder? Oder sind da noch andere caveeats? Script auf Netlogon und auf gehts. Auch wens natürlich immer noch mühsam bleibt. Vielleicht gehts sogar remote von einer anderen Maschine, habe ich noch nie probiert. In Powershell auf den Clients: Reset-ComputerMachinePassword -Server DCname -Credential Domäne\Benutzer Link bei MS: https://learn.microsoft.com/en-us/powershell/module/microsoft.powershell.management/reset-computermachinepassword?view=powershell-5.1 @TO: Was kam eigentlich dabei raus? Hast wie empfohlen professionelle Hilfe geholt? -
Anmeldung an Domäne wenn DC offline
Weingeist antwortete auf ein Thema von Moschi76 in: Active Directory Forum
Mal wieder eure Antworten verpennt... Sorry. Natürlich nicht, möchte ja grundsätzlich herausfinden worans happert. Aber wens zu lange dauert oder eben die Leute nicht arbeiten können aber sollten, wird mit dem Hämmerchen der Reflex provoziert. Aber klar, wäre auch der Moment wo ich einen Spezi holen würde wenn es länger nicht bemerkt wurde und ich mit dem Vergleich einer funktionierenden Umgebung sowie der Netzhilfe nicht weiter komme. Aber das läuft ja wohl auch noch, macht einfach stellenweise Probleme, sonst hätte es nicht monatelang unbemerkt bleiben können. Aber mal ehrlich, wann musstest Du den letzten DC wegen vermurkstem AD wiederherstellen? Ich sicher über 15 Jahre nicht mehr. AD ist doch recht statisch, also wozu der ganze Aufwand und das Risiko (Snapshots, versehentliche Restores usw. ) bei vermutlich keiner Ausfall-Situation wo ein zweiter DC tatsächlich dazu geführt hätte, dass die Mitarbeiter ohne Intervention des Admins hätten weiterarbeiten können? Auch Fehler werden repliziert. Und wenn die Leute nicht arbeiten können, was jucken dann 5min Restore-Time für einen DC? Sonst spricht man auch immer vom Aufwand/Ertrag. Ich verstehe es nicht, würde es aber gerne verstehen. Zugriff auf Backup zählt nicht, die sollten ja optimalerweise eine eigene, unabhängige Struktur haben. Wie immer für die Situation: keine Fremdprogramme wie Exchange die in der DB rumschreiben, relativ statisches AD, Wartungsfenster vorhanden von normal 5-15min pro Monat für Updates wo keine Anmeldungen am DC möglich sind (Zeit für ColdCopy + Reboot). Wer bringt das schlagende Argument? Ich konnte noch keines erkennen. Ich weiss man macht es nicht, aber das ist kein Argument oder? Wenn ich blind und ignorant bin, schiebe ichs einfach aufs fortschreitende Alter, aber interessieren würds mich trotzdem =) HostCrash hat normal nichtmal Auwirkungen auf ein statisches AD. Restores gabs bei mir nur bei Update-Runden. --> Beispiel: Defekter ComponentStore aus verschiedenen Gründen/Ursachen (Festplattenplatz, Updatereihenfolge usw), verbocktes Update von MS oder selber ne Timeline verbockt ( NTLM etc). Der Aufwand für das Beheben eines Store-Defekts - sofern er möglich ist - steht selten im Verhältnis zu einem Restore, selbst ein Neuaufsetzen wäre vermutlich schneller. Aber vielleicht bin ich auch einfach zu langsam/ungeschickt. Oder niemand prüft den Store nach den Updates auf Beschädigungen Kann leider nicht folgen. Wie kann das auf nem einzelnen DC passieren bzw. Auswirkungen haben? Er hat doch immer auf sich selber Zugriff und kennt sein aktuelles Maschinen-PW. Oder meinst was ganz anderes? Falls ja, was genau und wie kann ich es provozieren zur Test-Behebung? Wenn er der einzige ist, was hindert mich am Image-Restore/CopyPaste des DC vom Stand Tag davor. -
Anmeldung an Domäne wenn DC offline
Weingeist antwortete auf ein Thema von Moschi76 in: Active Directory Forum
Sorry wurde etwas später. Eure Argumentation verstehe ich durchaus und habe es auch jahrelang so gehandhabt. Und in grösseren Umgebungen ist das ja auch kein Thema. Da ist aber auch der Rest der Umgebung fehlertolerant ausgelegt. Und ja, sie fressen fast kein Heu, insbesondere als VM nicht. Aber der Unterhalt ist eben doch da und die Lizenzkosten auch. Bei physischen Maschinen war das auch noch was anderes da nicht in Sekundenschnelle der alte wiederhergestellt werden konnte. Nur musste ich über die Jahre feststellen, dass wenn es zu einem Ausfall kam, noch nie AD an sich der Verursacher des Problems war, aber doch schon ab und wann Kopfzerbrechen verursacht hat nach einem Problem wo z.Bsp. die Hardware, der Mensch oder ein Update schuld war. Die Reparatur nahm immer einiges an Stunden und teilweise Nerven in Anspruch. Die Erfahrung fehlt ja dann etwas wenn man nicht täglich solche Probleme hat. Gleichzeitig hatte ich nie Probleme in Kleinstumgebungen mit einem Server, auch wenn die Putzfrau versehentlich den Stecker gezogen hat oder die USV über den Jordan ging. Einschalten und lief einfach wieder. Völlig schmerzfrei. Da habe ich dann irgendwann angefangen nur noch auf einen DC zu setzen wo es möglich war. Im Endeffekt muss so oder so der PDC - auch wenn es nur noch eine Rolle ist - online sein bei den Dingen die wirklich Ärger verursachen können (DFS-Ziele umlegen z.Bsp.). Klar ist ein Designfehler wenn PDC-Emulator-Rolle auf dem gleichen physischen Server liegt wie das aktive PDC-Ziel. Ist aber schnell passiert und ein Design-Fehler der sehr oft vorkommt, auch weil den Leuten Jahrelang eingetrichter wurde, dass es den PDC nicht mehr gibt. Komplett vergessen ging bei den ganzen Belehrungen jeweils, dass die Abhängigkeiten von seinen Funktionen aber durchaus immer noch vorhanden sind. Auch heute noch. Sprich am Fakt das er da sein muss hat sich wenig geändert, trotz aller Begriffs-befindlichkeiten auf die man aus diesem Grund besser verzichtet hätte. Die Wahrscheinlichkeit das bei einem Hardwareausfall also der PDC bzw. der DC mit der PDC-Emulator-Rolle betroffen ist, liegt im KMU-Bereich in der Regel bei 50%. Also bringt mir diese Fehlertoleranz wenig bis nix. Jede Rollenübertragung und korekte Überprüfung und Neuanlegunge eines DC's brauchen länger als ein Restore. ;) Ich sage nicht, dass es der Weisheit letzter Schluss ist und die Meinung muss auch nicht jeder teilen und wenn jemand mit einem schlagenden Gegenargument kommt, bin ich nie abgeneigt meine Meinung zu ändern, aber ich persönlich sehe heute im Gegensatz zu früher keine effektiven Vorteile in mehreren DC's in Kleinumgebungen mehr. (Edit: Wenn dann für die Infrastruktur --> Ticket-High-Jack Problematiken). Einfach weil ein Restore eine Sache von Sekunden/Minuten und nicht mehr von Stunden ist, weil der DC heute ein File und keine physische Maschine mehr ist. Möchte aber nochmals betonen, das gilt ausschliesslich solange man nicht Daten im AD ablegt, welche für die tägliche Arbeit benötigt werden und permanent im AD rumgeschrieben wird. Ich persönlich habe diese Zöpfe mittlerweile fast alle aus Sicherheits- oder Komplexitätsgründen abgeschnitten. Ich versuche heute alles möglichst einfach zu halten und die Komplexität auf den Unterbau zu schieben. -
Anmeldung an Domäne wenn DC offline
Weingeist antwortete auf ein Thema von Moschi76 in: Active Directory Forum
Och das können doch durchaus auch mehr als eine handvoll User sein. Würde das eher an der Häufigkeit der Änderungen im AD festmachen (Exchange, ERP das die Kontakte nutzt etc.), wie Fehlertolerant der Rest der Umgebung gestaltet wird etc. Bei Passwort/Kerberos Rotierungen empfiehlt sich ja eh ein neues Backup. Stirbt ein physischer Server, ist bei vielen kleineren/mittleren Umgebungen eh meist soviel down, das nicht ohne Unterbruch weitergearbeitet werden kann/soll Backup/Restore Maschinen haben vorzugsweise eine eigene Rechtsstruktur, hilft also nicht für den Restore Die ganzen potentiellen Replikationsprobleme fallen weg Eine Wiederherstellung bei nur einem DC ist sehr fehlterolarant gegenüber den gängisten Fehlern punkto Sicherung/Wiederherstellung oder auch wenn Windows-Updates in die Hose gegangen sind. Eine DC VM ist ca. 25GB gross. Auf moderner Hardware ist die innerhalb 30 sek bis 5 min wiederhergestellt. Jede Prüfung der Replikation und allfällige Behebung von Problemen dauert länger als die Wiederherstellung. Lizenzkosten, Wartungskosten, Unterhaltskosten sind insgesamt tiefer Update-Handling bei der aktuellen Qualität der MS Updates ist einfacher (DC runterfahren, Cold-Snapshot/Kopie, hochfahren, Updates einspielen, Neustart). Das runterfahren, ziehen des Snapshots, hochfahren dauert weniger lang als irgend ein Update einzuspielen. Der effektive Ursprungszustand ist ebenso schnell wiederhergestellt, im Gegensatz zu Updates deinstallieren, was mal geht und mal nicht. Rollbacks wird es niemals geben). Aus sicherheitstechnischer Sicht ist eine Replikation immer eine potentielle Vergrösserung der Angrifssmöglichkeiten, auch wenn ich persönlich das eher schlecht abschätzen kann sondern nur schon entsprechendes über DHCP, DNS, WINS etc. gelesen habe und etwas schockiert über die teilweise Einfacheit war. Für mich vereinfacht es das Handling massivst, habe weniger Ärger (je älter ich werde, desto weniger Ärger-Tolerant bin ich) und ich muss weniger Stunden verrechnen. Aber eben, das ist nur meine Meinung und natürlich Immer in Bezug auf Grösse/Änderungen/Abhängigkeiten von AD -
Migration Windows Server 2012 R2 zu Windows Server 2022
Weingeist antwortete auf ein Thema von pischel in: Windows Server Forum
Ich kann keinen Grund der dagegen spricht erkennen... Wir sprechen hier von Minuten, nicht Tagen wo ein DC runtergefahren ist und wieder hochgefahren wird. Auch eine Stunde ist bestimmt noch kein Problem, gibt ja kaum viele Änderungen im kleinen Umfeld. Da waren die Updateeinspielungen unter 2012 manchmal schon länger. -
Migration Windows Server 2012 R2 zu Windows Server 2022
Weingeist antwortete auf ein Thema von pischel in: Windows Server Forum
Gegenfrage: WAS genau spricht denn dagegen ausser das es 5 minuten mehr Arbeit gibt aber vielleicht Ärger verhindern kann weil irgendwo Probleme auftreten? Ich versteh das immer noch nicht sorry. Der Zusatzaufwand steht in keinem Verhältnis zum potentiellen Ärger. In Kleinumgebungen ist es nunmal so, dass die Wahrscheinlichkeit hoch ist, dass es irgendwelche Abhängigkeiten gibt. Wenn etwas nicht klappt, kann ich die Maschine wieder einschalten, das ganze analysieren und den neuen DC in einem Wartungsfenster runterstufen. Ich lief da schonmal mächtig rein mit tausenden von Dokumenten die auf nem DC was verknüpft hatten statt per DFS. DAS gibt eine enorme unnötige Unruhe in den Betrieb und Stunden unterbruch. Das Wiedereinschalten des DC's wäre in 2min erledigt. Klar das war ein Designfehler meines Vorgängers bzw. eines Dienstleister, aber wo kann man sowas schon 100%ig ausschliessen. *schulterzuck* -
Anmeldung an Domäne wenn DC offline
Weingeist antwortete auf ein Thema von Moschi76 in: Active Directory Forum
Das kommt ganz darauf an wie man es konfiguriert. Standardmässig geht das, wenn man das abgewöhnt, nicht. Was nun sinnvoller ist bzw. ob es ein effektiver Sicherheitsgewinn ist, wenn man dies verhindert, da scheiden sich die Geister äh Sicherheitsspezis. -
Die Empfehlung ist vor allem aufgrund der Performance. Virenscanner generieren sehr viel Last. Prozessor als auch IO's bei meistens effektiv wenig Nutzen im Schadensfall da moderne Schadware die einigermassen Up to Date ist, den Kram einfach "übergeht". Die Filewalker der Scanner waren auch schon selbst das Ziel, sprich wird die Datei vom Scanner geöffnet, wird die Schadsoftware aktiviert. Ist daher immer so eine Sache. MS macht da eine Mischrechnungs-Empfehlung welche eben das alles etwas berücksichtigt. Daher sind auch zusätzliche Virenprogramme oft eher hinderlich. Weil sie so tief ins System eingreifen und volle Rechte haben, sind sie eben auch ein beliebtes Einfallstor. Hilft ja nichts, wenn der Virenscanner die Kisten vollständig oder sehr stark auslasten und man nicht mehr arbeiten kann.
-
Windows 10 Updates verhindern
Weingeist antwortete auf ein Thema von RealUnreal in: Windows 10 Forum
Die ganzen GPO's welche den Updatedienst deaktivieren/steuern sollen sind nur beschränkt tauglich wenn man wirklich auf auf die Steuerbarkeit angewiesen ist. Das Verhalten wurde innerhalb der verschiedenen W10 Builds mehrfach geändert, die Auswertung bzw. Einstellungen ignoriert etc. damit es den Admins zu viel wird mit den ganzen Änderungen und die Updates Ihren Weg an den Admins vorbei auf die Kisten finden. Sei es via anderen PC's, Online via MS an (fast) allen Verhinderungs-Einstellungen vorbei. Daher ist es auch viel einfacher überall die identischen Builds einzusetzen, dann reagieren wenigstens alle gleich. Bezüglich dem Task: Ja dann werden Systemrechte benötigt, das geht noch. Lästiger wirds mit dem Zeugs das TI-Rights benötigt. Allgemein ist es bei solchen Tweaks zu empfehlen, das ganze per Script und Gegenscript zu lösen und sauber zu dokumentieren oder eben per GPO setzen (mit Doku der Ursprungswerte). Auch schaue ich immer, dass die ursprüngliche Rechte erhalten bleiben, also lieber dem eigenen Script die entsprechenden Rechte verschaffen als die benötigten Zugriffs-Rechte der Hives an sich zu überschreiben. -
Windows 10 Updates verhindern
Weingeist antwortete auf ein Thema von RealUnreal in: Windows 10 Forum
Ich glaube nicht, dass er durch eine reguläre GPO deaktivierbar ist. Habe damals nichts dergleichen gefunden. MS will das ja auch gar nicht regulär verhinderbar machen sondern nur mit erhöhtem Aufwand. Daher per Reg-Tweak welcher per GPO bzw. GPP erreicht werden kann. Die genau benötigten Rechte weiss ich grad nimmer auswendig. Entweder Admin, System oder Trusted Installer. Soweit ich mich erinnere warens reine Admin-Rechte. Allerdings nicht per GUI sondern wirklich per Registry. Aber eben, der zugehörige Task/Aufgabe muss auch deaktiviert werden, sonst ist das Teil schnell wieder online. ;) Der Task ist: \Microsoft\Windows\WaasMedic\PerformRemediation (nur zu sehen mit Admin-Rechten, sonst ist er unsichtbar) -
Windows 10 Updates verhindern
Weingeist antwortete auf ein Thema von RealUnreal in: Windows 10 Forum
Danke für die Info. Windows 10 hast ein LTSC oder IoT im Einsatz damit keine grossen Upgrades gefahren werden? Habe ja auch gezwungenermassen unfreiwillig ein paar solcher Krücken im Einsatz. Einen Scanserver übrigens auch mehrfach, allerdings aus anderem Grund (NTLM). Ich persönlich würde den Rechner nicht ins Hauptnetz nehmen. Aber wurde ja schon hinlänglich breit geschlagen. Habe dafür einen allfälligen Lösungsatz. Da Du mit VmWare arbeitest, könntest Du das ganze entkoppeln - VM1 hat die Verbindung zum Scanner aber nicht ins Netzwerk - VM2 hat die Verbindung ins Netzwerk aber nicht zum Scanner Für die Scans verwendest Du eine Platte die für beide VM's mit einem Physical Shared Controller angebunden ist. Wichtig hierbei ist, dass die Indexdienste auf der Platte auf beiden Seiten deaktiviert werden, da es ansonsten Theater gibt weil beide VM's gemeinsam schreiben könnten und NTFS ja kein Cluster-Filesystem ist. Schon gar nicht wenn sie voneinander nichts wissen. Ist zwar für ein solches Laufwerk nicht schlimm, aber dennoch nervig. Optimalerweise haben auch nur Benutzer von VM1 Schreibzugriff und die Ordner werden z.Bsps. in der Nacht per Script geleert. Müssen die beiden VM's "kommunzieren" bzw. beide schreiben, kann man das z.bsp. mittels einem Lock-File/Kommunikations-File und Scripts die per Aufgabe gestartet werden, erschlagen (oder einem eigens programmierten Dienst). Ist ziemlich primitiv und je nach Aufgabe auch etwas aufwendiger wenn zeitnahe Nutzerinterkation gefordert ist, funktioniert aber. Im Endeffekt macht VmWare für ihr VMFS auch nichts anderes, wenn auch technisch ausgefeilter ;) Klappt aber auch nur, wenn die Software nicht noch irgendwleche User-Verwaltung bewerkstelligen muss damit nicht jeder ide Scans sieht. Auch wenn das auch über definierte Zielordner auf dem Scanner gelöst werden kann. Nope das reicht schon länger nicht mehr aus. Man muss den Medical Service deaktivieren, die Übermittlungsoptimierung, den regulären Update Service und die Aufgabe wo mir jetzt der Name grad spontan nicht einfällt aber einfach zu finden ist, welche den Status des Medical Services überwacht. Ansonsten klappt das nicht zuverlässig. Ich sperre zusätzlich die Kommunikation per Windows-Firewall. Am besten per Script ein und ausschalten. In der Nacht läuft jeweils das Auschalt-Script, sollte man vergessen das gaze wieder zu deaktivieren nach einer Update-Runde. Der Medical Service überwacht z.Bsp. auch ob wirklich svchost.exe hinterlegt ist, man kann das also auch nicht ohne weiteres verbiegen. Mittlerweile ändere ich die svchost.exe für die Update-Dienste auf einen eigenen Hardlink damit ich zuverlässig die Kommunikation der Update-Dienste per Firewall unterbinden/erlauben kann, damit bei Industrie-Steuerungen zuverlässig ein selber bestimmtes Update-Fenster erzwungen werden kann, gleichzeitig bei einer Fernwartung aber z.Bsp. keine Updates über die Rechner der Servicetechniker gezogen werden. Bei IoT wäre das wohl einfacher, aber bis das in der Industrie durch ist.... die nehmen lieber Pro..... Ansonsten: Ich wüsste nicht wie man als Kleinfirma einen grossen Hersteller dazu überreden kann, LTSC oder IoT zu verwenden. Machen die wenigsten. Da heisst es dann, kaufen sie doch die Maschine irgendwo anders. Machen wir nicht solange die grossen das nicht haben wollen. Manchmal hilft der Gang zur GL und Erklärung der Sachlage dann klappts vielleicht, aber meist auch dann nicht. So nach dem Motto, wir ändern nichts das funktioniert, wir prüfen das in Zukunft. Solange also kein gorsser Kunde das Messer ansetzt, ist denen alles egal ;) -
Windows 10 Updates verhindern
Weingeist antwortete auf ein Thema von RealUnreal in: Windows 10 Forum
Das hilft heute nicht mehr zuverlässig. ;) Dieser Umstand kostete in einer meiner Umgebungen schon ein paar flotte tausender. Du musst auch die dazugehörigen Überprüfungsaufgaben/Services deaktivieren sonst ist der ganz schnell wieder aktiv wens den Kontrollmechanismen grad in den Kram passt. Meist stört aber weniger das Update selbst, sondern der Installationszeitpunkt. Ansonsten: Mich würde interessieren welches Sicherheitsupdate (Jahr/Monat) bei welcher Windows 10 Version Ärger macht und welche Software die Updates nicht mag. Oft hiflt es LTSC/IoT zu verwenden. Da wird bei den Updates eigentlich ziemlich stark darauf geachtet, das die API's, Module, Syntax etc. identisch bleiben. Sprich läufts da einmal drauf, ist die Chance sehr gross, dass es auch mit Updates weiterläuft. -
Migration von 2008R2 nach Windows Server 2019
Weingeist antwortete auf ein Thema von AIKIDO in: Windows Forum — Allgemein
Meinte natürlich 2022 nicht 2021 -
Migration von 2008R2 nach Windows Server 2019
Weingeist antwortete auf ein Thema von AIKIDO in: Windows Forum — Allgemein
wieso eigentlich nicht grad auf das neueste LTSC Build? 2021 läuft fast seit Tag 1 sehr stabil. -
Vielleicht könntest in ein altes Image die Konfig einpflegen? Das Industriezeugs ist zwar gerne recht zickig aber oft doch ziemlich primitiv aufgebaut. Da die Maschinen welche W7 haben mittlerweile aus der Garantie etc. rausgeflogen sein dürften, könntest du auch probieren, die Software auf W10 LTSC umzuziehen. Dann hättest wieder ~7-10 Jahre Ruhe. Stolpersteine sind aber gerne mal die doofen HDMI-Kopierschutzfunktionen. Da Vista/W7 den direkten Hardwarezugriff gegenüber XP nochmals stark eingeschränkt hatte, stehen die Chancen gar nicht mal so schlecht, dass es funktioniert. Je nach dem zusammen mit den Programmkompatibilitäts-Tools (Recht zeitaufwendig wenn man da manuell eingreifen muss aber in der Regel bekommt man alles zum laufen). Oder vollständige Netztrennung. Ich weiss, teilweise super mühsam ist mit den hochintegrierten Systemen.
-
Verknüpfungen zu Dateien ändern sich automatisch
Weingeist antwortete auf ein Thema von Gu4rdi4n in: Windows 10 Forum
Ich vermute stark dafür ist der dienst "TrkWks" zuständig. Überwachung verteilter Verknüpfungen. Die Beschreibung passt jedenfalls: "Hält Verknüpfungen für NTFS-Dateien auf einem Computer oder zwischen Computern in einem Netzwerk aufrecht." Ob man das per GPO steuern kann, weiss ich nicht. Bei mir ist der Dienst jeweils deaktiviert. -
Server mit zwei DNS-Namen verknüpfen?
Weingeist antwortete auf ein Thema von Volker Racho in: Windows Server Forum
Also wenn der alte Server nur noch Fileserver ist, dann laufen doch auch all die Freigaben dieser Programme noch oder? ;) Allenfalls heisst dann der Filer halt noch DC1 obwohl er es nicht ist. Das wäre die Variante wo nix auf die Füsse fällt. Auch wenn ich diesen Server dennoch neu installieren würde weil es eben mal ein DC war. Alias-Namen für Freigaben ist immer mit einem Risiko für Ärger verbunden. Nicht alles kann damit umgehen. Nichtmal Windows selbst so richtig. Sind doch ein paar Stolpersteine die man eigentlich nicht wirklich will. Wenn Du gewillt bist die Arbeit zu machen, dann gleich komplett. Also File-Datenzugriff unabhängig zum Servernamen machen. --> DFS Da will man dann vielleicht auch, dass es auf die Schnautze fällt. Um zu erkennen, was noch auf den Servernamen zugreift. Vielleicht aber auch nicht. Je nach Menge der betroffenen Dokumente. Komplette Neuinstallation einer Anwendung selber ist wohl selten bis nie notwendig. Dürfte alles verhälnissmässig einfach änderbar sein. Wenn sie tatsächlich in der Exe hardcoded ist, auch kein Problem. Ist ja fix geändert durch den Hersteller. Exe tauschen fertig. ist in der Regel liegt das Problem aber eher daran, dass viele Software die Pfade in den Dokumenten selbst speichert. Je nach Anzahl wird das enorm lästig.