goat82
-
Gesamte Inhalte
322 -
Registriert seit
-
Letzter Besuch
Alle erstellten Inhalte von goat82
-
DHCP LB in hot Standbye Mode ändern währen dem Betrieb
goat82 antwortete auf ein Thema von goat82 in: Windows Server Forum
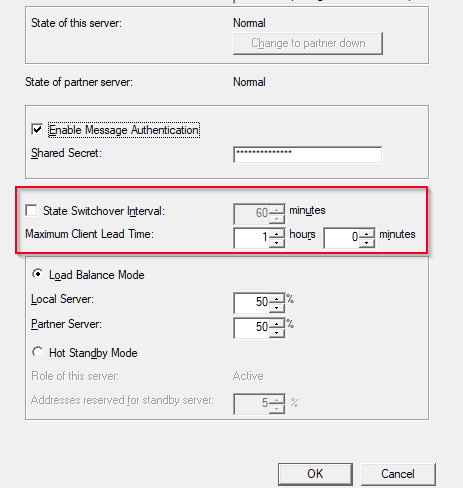
Wenn du ein normaler Scope mit 256 Adressen hast und ein LB dann wären 50 50 ja jeweils 128 Adressen. Ich denke das sollte bei jedem KMU schnell erreicht sein. Wenn ein Pool im 50 50 LB Betrieb erschöpft ist und der 2. DHCP offline ist, dann stellt der DHCP seine Arbeit ein. So konnte ich es jedenfalls feststellen. Darum möchte ich in den Hotstandbye wechseln. Überschreibt die markierte Option "Maximum Client lead time, die Lease time im Scope und gilt nur, wenn der Hotstandbye einspringt ? Das würde so für mich Sinn machen. Denn so kann, wenn der Primäre DHCP wierder online ist schnell wieder übernehmen. Die Option "State switchover intervall" sagt dann vermutlich aus, wann wieder auf den ausgefallenen Server zurückgewechselt werden soll, vermute ich mal. Passt das so ? Sorry aber hier fehlen mir die Erfahrungswerte. -
DHCP LB in hot Standbye Mode ändern währen dem Betrieb
goat82 antwortete auf ein Thema von goat82 in: Windows Server Forum
Kann mir jemand erklären wie es mit den 2 Feldern aussieht, wenn man den Hot Standby aktiviert?
-
DHCP LB in hot Standbye Mode ändern währen dem Betrieb
goat82 antwortete auf ein Thema von goat82 in: Windows Server Forum
Ein Server braucht unter Last mehr als 50% der zugewiesen Adressen und ist mit 505 50% so in der LB Einstellung nicht alleine zuverlässig lauffähig. Mt Hot Stand Bye kann ein Server alles halten und beliebig bei Windowsupdates usw. herunterfahren. Wir haben somit weniger Administrationsaufwand und Abhängigkeiten und dennoch eine Ausfallssicherheit. -
DHCP LB in hot Standbye Mode ändern währen dem Betrieb
goat82 hat einem Thema erstellt in: Windows Server Forum
Hallo Zusammen, weiß jemand ob es eine DHCP Downtime gibt, wenn man von einem DHCP LB auf Hot Standyby umstellt ? Es sind ca. 700 IPs 50% 50% vergeben. Die Provisorischen 5% bei "adresses reserved for standby server" müssten dann doch auf 100% gestellt werden oder ? Wenn der aktive DHCP Server ausfällt soll der Hot Standybe ja mit 100% einspringen oder habe ich einen Denkfehler ? Weiß jemand ob die State Switch Option die Funktion ist wo hier z.B. alle 60 Min geschaut wird ob der offline gegangene Master wieder online ist ? Macht für mich als einigestes Sinn. Sorry hatte bisher nie mit DHCP Failover das Verknügen, da bisher immer einer ausgereicht hatte. Was ist die Option Maximum Client lead time? Ich würde sagen das ist die Lead Time für den eingesprungenen Server. Dieser hat dann zwar deutlich mehr Last weil ja alle 60 min die Adressen erneuert werden, dafür gehen die Leases auf den aktiven DHCP wieder schneller über, denn hier ist ja in der Regel eine längere Lease von mehreren tagen eingestellt. LG Goat
-
Zugriff auf Domainecontroller bei Netzwerkausfall sicherstellen mit Protected user aber wie ?
goat82 antwortete auf ein Thema von goat82 in: Active Directory Forum
Ok verstanden, vielen Dank. Was ist aber auf einem RO DC ? -
Zugriff auf Domainecontroller bei Netzwerkausfall sicherstellen mit Protected user aber wie ?
goat82 antwortete auf ein Thema von goat82 in: Active Directory Forum
Ok. Mit lokal anmelden meinst du da einfach an der Domaine ohne Netzwerk anmelden oder wirklich lokal mit dem Domainenuser über Domaincontrollername\Domainuser. Lokale KOnten gibts ja nicht am DC -
Zugriff auf Domainecontroller bei Netzwerkausfall sicherstellen mit Protected user aber wie ?
goat82 antwortete auf ein Thema von goat82 in: Active Directory Forum
Ich glaube ich habe mich falsch ausgedruckt. Das AD hat 1000 Domainuser. Davon haben 10 Domainadminrechte. Es gibt 5 Domaincontroller und 10 RO Domaincontroller. Wenn alle 10 Domainadministratoren in der Protected Usergruppe sind und das Netzwerk wegfällt wie kann man sich dann an den Domaincontroller anmelden ? Es können sich ja nur Domaineadministratoren auf den Domainecomputer anmelden und wenn das Netzwerk weg ist und die Passwörter nicht gecached werden wegen der Protected Usergruppe, wie soll das gehen ? Oder betrifft das ganze mit dem Passwortcache nur RDP Anmeldungen ? Falls ja dann könnte man auch ohne Netzwerk sich am DC über die Console (Idrac oder Vsphere) als Protected User anmelden ? -
Zugriff auf Domainecontroller bei Netzwerkausfall sicherstellen mit Protected user aber wie ?
goat82 antwortete auf ein Thema von goat82 in: Active Directory Forum
Wie soll das gehen ? Anstatt Domainadminuser@Domaine.com Domaincontrollername\Domainadminuser ? Falls ja das funktioniert nicht. -
Zugriff auf Domainecontroller bei Netzwerkausfall sicherstellen mit Protected user aber wie ?
goat82 hat einem Thema erstellt in: Active Directory Forum
Hallo Zusammen, unsere Domainadministratoren sind Mitglieder der Protected Gruppe also können Sie kein NTLM und es werden auch keine Passwörter auf den Server gecached. Lokale Konten gibt es am DC ja nicht. Ist das Netzwerk nun tot, wie kann man sich dann am DC noch anmelden ? Die Administratoren sind Member der AD\Buildin\Administratorengruppe aber das hilft ja wenig wenn die User Member der Protected Usergruppe sind. Habe ich einen Denkfehler ? Aus Sicherheitsgründen haben wir einen einzigen Domainenadmin welcher kein Protected User ist. Hier müsste man aber mal sich alle paar Wochen an den DCs anmelden damit das Kennwort gecacht bleibt und der Zugriff sichergestellt werden kann. Gerne hätte ich hier eine andere Lösung mit 100% Protected User aller Domainenadmins oder zumindest die Gewissheit wie man sich an den DCs anmelden kann wenn kein Netzwerk besteht. Vielen Dank für euren Rat Lg Goat -
Wsus Updateserver herausfinden und in FW eintragen
goat82 antwortete auf ein Thema von goat82 in: Windows Server Forum
ja, danke. Leider benötige ich aber die IPs, da die Firewall keine URLs akzeptiert. Wahrscheinlich geht es dann nicht da für * ja sicher hunderte Server hinterlegt sind -
Wsus Updateserver herausfinden und in FW eintragen
goat82 hat einem Thema erstellt in: Windows Server Forum
Hallo Zusammen, erstmal wünsche ich allen ein schönes, neues Jahr. wir müssen den Internetverkehr aus SIcherheitsgründen extrem einschränken. Gibt es irgendwo eine öffentliche MS Destination Netzwerkliste wo alle MS Updateserver aufgelistet sind welche man in der Firewall eingeben kann ohne das man das Internet vom lokalen Wsus Server nach WAN-any komplett aufzumachen muss ? VIelen Dank für die Info. Goat82 -
Protected User Gruppe Zugriff auf \\domain.local erlauben nur wie?
goat82 antwortete auf ein Thema von goat82 in: Active Directory Forum
ja \\domain.local\netlogon und \\domain.local\sysvol geht, \\localhost\ und \\locale DC ip\ geht ebenfalls. \\donain.local\ geht aber nicht. Immerhin gibts so einen Workarround, wenn auch die DFS-N Problematik noch besteht. Immerhin geht DFS-N wenn man \\DC\Namespace\ eingibt noch. -
Protected User Gruppe Zugriff auf \\domain.local erlauben nur wie?
goat82 hat einem Thema erstellt in: Active Directory Forum
Hallo Zusammen, ich habe einige priviligitierten Konten u.a. Domainadminaccounts in der Protected Usergruppe. Funktioniert alles ganz gut, nur wie kann ich den Zugriff auf \\domain.local freigeben ? Probem ist auch das wir viel DFS-N im Pfad \\domain.local\xxx\xxx haben und abrufen bzw. testen müssen und die Domainadmins natürlich auch auf sysvol+Policys drauf sollen. (Geht natürlich auch über C:\Windows\sysvol) und auch DFS-N geht mit jedem anderen User außerhalb der Protected Usergruppe aber der Mensch ist ein Gewohnheitstier) PS: Der Zugriff in der Protectedgroup über \\x.x.x.x funktioniert nur nicht über den DNS Namen. Daher freue ich mich über eine Hilfe wie man \\domain.local innerhalb der Protectedgroup aktivieren kann, falls es geht. Lg Goat -
Repadmin /replsum Fehler total und % Statistik löschen
goat82 hat einem Thema erstellt in: Active Directory Forum
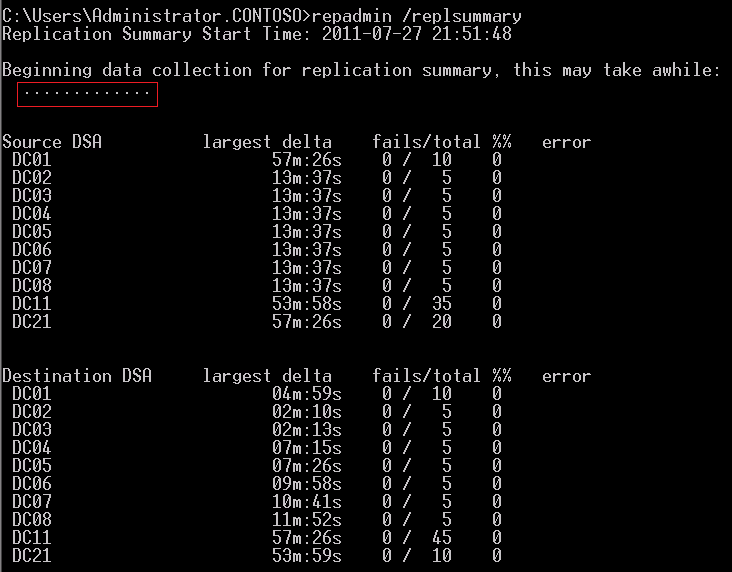
Hallo Zusammen, wir hatten einige Zeit Replikationsprobleme und daraufhin neue DCs installiert. Nun läuft wieder alles rund. Wegen der Optik und Statistik würde ich gerne die Werte unter total und % resetten lassen, damit wieder alles schön aussieht. Ich habe aber leider keinen Befehl hierfür gefunden. Hat mir jemand einen Tipp ? Eine weitere Frage hätte ich zur Replikation bzw. dem Delta. Hier ist überall 2h eingestellt. Sehr oft sehe ich bei Repadmin/replsum aber ein Delta von 2,5h daher vermute ich mal dass alle 2,5- max 3h eine Replikation durchgeführt wird. Kann es sein dass die 2h nicht so genau genommen werden ? Es betrifft hauptsächlich Remotestandorte. Zeit ist überall via NTP und PDC verteilt und sollte kein Problem sein. LG Felix
-
Lokale User auf einem DC entfernen
goat82 antwortete auf ein Thema von goat82 in: Active Directory Forum
1. Alle eingetragen User sind Domainuser, keine lokalen User! 2. Das weiß ich nicht. Es sind einige Policys aktiv aber ich dort nicht, wie die Einträge zustande kommen. Wie kann es zu 1. kommen und ist es wirklich kein Problem ? Es sind hier neben Domainadmins auch User gelistet welche auf keinen Fall auf den DC kommen dürfen (auch nicht readonly). Diese User haben keine Domanandminrolle zugeweisen stehen aber auf dem DC in dieser lokalen Accessliste, warum auch immer. -
Lokale User auf einem DC entfernen
goat82 antwortete auf ein Thema von goat82 in: Active Directory Forum
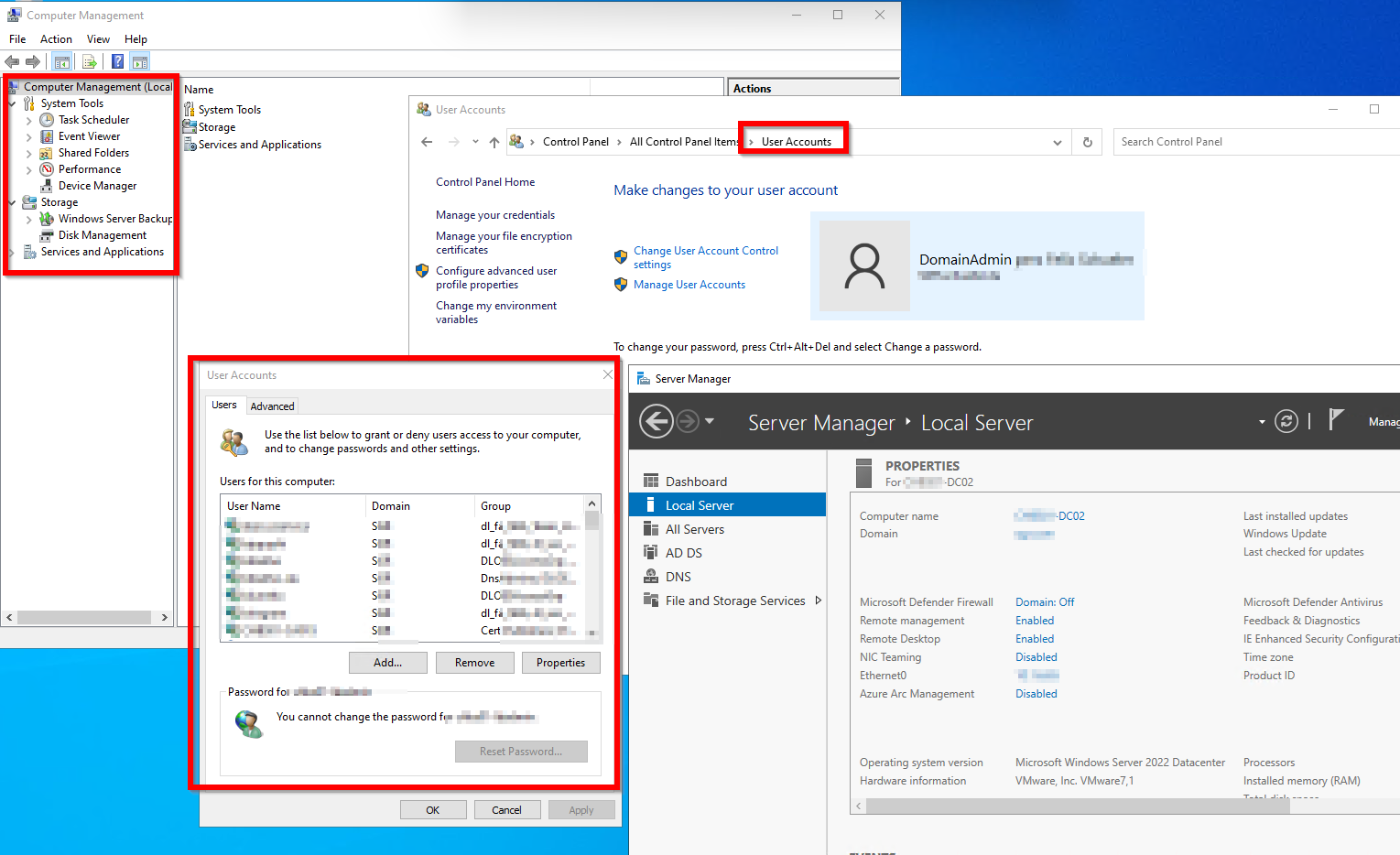
Es sieht genau so aus wie auf einem Memberserver nur dass unter Conputer Management die lokalen User fehlen, siehe Anhang. Gehe ich auf Users über das Controllpannel werden aber viele User berechtigt angezeigt. Die User kommen aus verschiedensten Sicherhietsgruppen. Und ja, das Problem ist auf einem DC und nicht auf einem Memberserver!
-
Hallo Zusammen, wir haben 5 2022 Domaincontroller welche 2019 DC abgelöst haben. Nun ist es eigentlich ja so, dass die lokale Userdatenbank auf einem DC per default abgeschaltet ist aber nicht bei uns! Die berechtigten User kommen aus den unterschiedlichesten Sicherheitsgruppen und scheinen wohl über ene GPO gekommen zu sein. Versuche ich einen User zu entfernen, hängt sich die Konsole User auf dem DC auf. Hat jemand eine Idee ? Ich habe auch leider die GPO welche das ganze verursacht hat noch nicht gefunden. Zumindest war es noch keine der angewendeten GPOs Lieben Gruß Felix
-
Freigabe und Sicherheitseinstellungsänderungen loggen aber wie ?
goat82 hat einem Thema erstellt in: Windows Server Forum
Hi Zusammen, ich habe viele Freigaben die per Zugriffsberechtigung auf die Freigabe und über die NTFS Ordersicherheitseinstellungen geregelt sind. Ich möchte nicht den einfachen erfolgreichen oder fehlgeschlagenen Dateizugriff loggen, sondern nur erfahren wenn auf eine Freigabe oder ein NTFS Ordner eine Berechtigung entfernt oder geändert oder wenn ein NFTS Ordner gelöscht wird. Funktioniert das irgendwie mit Hausmittel? Danke für euche Tipps. LG Gost -
Das mit dem Jumphost und der Devicecal verstehe ich nicht. Ich bezahle eine Device CAL für ein Device an dem sich x User anmelden können. Soweit so gut. Vermutlich bedeutet diese Device cal nur, dass sich x User über das Device anmelden können aber nicht gleichzeitig korrekt ? Warum es nicht erlaubt sein sollte dies über einen virtuellen Jumphost zu realisieren verstehe ich nicht. Ein Device ist ein Device egal ob Blech oder Virtuell oder verstehe ich etwas falsch. Genau das wäre meine Lösung mit dem jump Host, vorausgesetzt es ist legal. Auf dem RDS Server ist eine Projektsoftware installiert die von mehreren Servicemitarbeitern für den Kundeneinsatz genutzt wird. Die Projekte und die Servicemitarbeiter sind hier aber nicht fest zugeteilt, die Projekte laufen auch unterschiedlich lang und haben auch unterschiedlich viele Servicemitarbeiter. Gibt es ein neuen Auftrag, benötigen neue Servicemitarbeiter Zugriff für X Wochen. Wird ein Kollege Krank, muß der Kollege einspringen usw.
-
puh, danke erstmal für die 2 Antworten. Wie wäre es wenn ich eine VM als Jump Host erstelle und zu den 10 USer Cals eine oder zwei Device Cals kaufe. Können sich dann alle User mit ihrem persönlichen AD Login auf dem Jump Host anmelden und von dort eine Verbindung mit dem RDS Server aufbauen sodass z.B: 10 User sich die beiden Lizenzen teilen ? Hintergrund ist nicht der Geiz, sondern, dass das System von mehreren Personen kurzfristig genutzt werden soll. Der Personenkreis ändert sich oft. Eine User Cal mit 60-90 Tagen Beschränkung ist daher nicht so zielführend.
-
Hi Zusammen, wir haben einen RDS Server mit 10 User cals. Da MS ja die Lizenz außer bei der Console oder mit /Admin beim einmaligen Anmelden für 60 Tage sperrt überlege ich einen Shared User "Gemeinsamer User" anzulegen. Dieser könnte dann von verschiedenen User jedoch nie gleichzeitig benutzt werden. Die Nachweispflicht bzw. wenn jemand etwas löscht oder Unsinn treibt kann bei dem Terminalserver vernachlässigt werden. Toll wäre wenn das A legal ist und B so funktioniert dass ich am Ende von 8 festen User CALS 2 für Shared Nutzer habe, welche sich wirklich nur selten anmelden werden. Arbeitet "Gemeinsamer Nutzer1", soll beim erneuten Verbinden mit einem anderen User mit dem selben Login "Gemeinsamer Nutzer1" die Meldung erscheinen. "Benutzer oder Session bereits aktiv, damit der neue Benutzer weiß dass ein Kollege bereits arbeitet und sich nicht am Terminalserver abgemeldet hat. So könnte er dann den Login mit dem eingerichteten "Gemeinsamer Nutzer2" versuchen. Kann mir jemand etwas zu A und B sagen ? Besten Dank LG Felix
-
Ich kenne wirklich keinen Betrieb der eine VMwareumgebung hat und keine VM Snapshots einsetzt. Insbesonde vor wichtigen, kritischen Softwareupdates oder sonstigen Installationen. Diese Revertmöglichkeit mit einem Rollback in Sekunden bietet glaube ich kein anderes System, von demher ein absoluter Pluspunkt. Klar ist ein Snapshot kein Backup und ein ESX, Storage und Vcenter gehört immer überwacht und bestenfalls redundant ausgelegt, wenn es das Budget hergibt. Und logisch kosten Snapshots immer performance und sind unflexibel, da man die VM nicht ändern kann, wenn Snapshots existieren. Bei uns werden Snapshots automatisch gelöscht wenn Sie älter als 2 Wochen sind, zumindest im Vcenter. Auch ich kenne das Problem mit vollem Storage oder ESX durch Snapshot, hatte ich auch schon 3-4mal erlebt aber hier sehe ich das als keinen Fehler an auch kein Nachteil am System VM oder "Snapshot" sondern eben ein Fehler des Admins wenn er den Speicher oder seine Aufgaben nicht im Auge hat. Alles Theorie und Praxis, der Rest ist Lehrgeld. @Daabm. GPO und Logonscripte haben mit DFS miteinander zu tun, zumindest in meinem Fall. Wenn Gpos und Logonscripte auf Freigaben auf Server B zeigen welcher via DFS-R auf Server A repliziert wird. 60% der User aber diese GPO nicht haben und per Namespacereferal auf Server A gehen ist logisch das es unpassend ist die Daten auf beiden Servern im doofsten Fall gleichzeitig zu laden und hin und herreplizieren und wenn dann noch gleichzeitig ein Backup streiklen sollte auf einem Server ist der Datenverlust und das Geschrei groß......... Ich bin hier um Lösungen zu erfragen, mehr nicht. Das die derzeitige Umgebung höchst unprofessionell und strittig ist ist, weiß ich ja selbst Gibt es nun eine gute Alternative ?
-
Also so langsam glaube ich ist alles auf einem guten Weg. DFS läuft nun seit 3 Tagen zwar mit jede Menge Warnungen, siehe unten, aber es läuft. Es dauert eben Tage bis die Backlogs abgearbeitet sind. Ich habe es nur hinbekommen indem ich das NTFS Journal erhöht habe. Hier war noch 512MB eingestellt, eindeutig zu wenig für x Millionen Daten. Zudem habe ich einzelne Replikationsgruppen nach und nach auf eine höhere Statinggröße gezogen. Dies konnte ich nicht gleichzeitig machen, da die Backlogs und Konflikte im DFSPrivate Ordner sich angesammelt haben und so wäre mir die Disc vollgelaufen - Ein Todesstoß von hinten , sozusagen. Ich hoffe, dass nun alle Ordner abgearbeitet werden und es nun hoffentlich eine Zeit lang läuft. Spätestens nach 10 Tagen ist aber wieder die DFS Datenbank zerschossen und ich muss 7h ein chkdsk machen. Mal sehen ob es nun besser läuft. Wenn ja, habe ich Zeit die gemachten Fehler zu korrigieren. Es existiert natürlich ein funktionelles Backup, welches aber nicht performt, denn der Restore der 25 TB dauert >24h. Ein Chkdsk /F dauert ca. 5-7h Bevor man an ein Konzept geht muss man erst mal reverse engeneering machen und das alles sauber analysieren und dokumentieren. Es gibt hunterte GPOs, login Scripte usw. die da reinwursteln. Natürlich würde ich niemals so viele Daten auf einem Volume und auch niemals mit DFS-R synchronisieren aber hier ist bzw. war es immer so. Ich würde im ersten Schritt, wenn die Daten via DFS-R hoffentlich synchron sind erstmal die direkten Freigabeberechtigungen von Server B nehmen, dann läuft DFS-R sicherlich auch mit weniger Konflikten. Dann kann man schauen was möglich ist. Aufgrund den Broadcom Vmware Mondpreisen überdenken ja auch viele Ihre Infrastruktur oder schauen sich andere Anbieter an. In diesem Fall ist es auch gerechtfertigt, da es ein Stand Alone ESX ist mit nur 3 Vms ist (File, DNS,DHCP). Hier würde sich ggf. eine Windowsmaschine / Cluster/Storage Replica / Andere Lösung mit dem anderen Stand alone Host anbieten. Die Vorteile von ESX (Snapshots, HA, Vmotion usw.) wurden auf diesen beiden Stand alone ESXi nie genutzt. The DFS Replication version vector size has exceeded acceptable limits. The DFS Replication version vector size has reached back to the acceptable limits. )
-
Hi Daabm, das Konzept war vor 15 Jahren sicher angemessen. Nun sind die Daten halt mehr als angewachsen und das ganze wurde mehr als Stiefmütterlich behandelt. Der Grund liegt an den fehlenden Resourcen. Nun kann man natürlich meckern und die Ferrilösung anbieten, aber ich kann beim besten Willen auf die Schnelle kein Ferari herzaubern. Es handelt sich um ein produktives System und um keine Spielewiese. Selbst wenn ein Storage Replica oder anderes umgesetzt werden würde, müsste ich zuvor die Datenkonsistenz von Server A und B wiederherstellen. Die Daten sind von beiden Server in Zugriff (>400 User). Ich kann hier auch nicht einfach mal rumspielen, Replikationspartner oder Freigaben löschen und das Ganze auf die Harte Tour gerade biegen bis ein angemessenes, natürlich besseres Konzept angewendet werden kann. Daher möchte ich erstmal die Daten von Server A und B auf einen Stand bringen (am liebsten via DFS wenn es vernünpftig und performant laufen würde), Server B vom Zugriff und von den Replikationsgruppen entfernen und dann ein neues, sauberes Konzept erstellen und umsetzen mit den MIttel die da sind. Hier nehme ich gerne Rat und Vorschläge an und behare nicht auf das alte und langsame DFS-R. Ein gespiegeltes Rechenzentrum, Vsphere Cluster oder ähnliches steht aber nicht zur Verfügung. Ebenso ist primäre Aufgabe die Datenkonsistenz wiederherzustellen auch wenn ich nicht denke das dies mit DFSR erreicht werden kann, weil es einfach zu viele Daten sind. (Delta ist nur 400GB und nur ca. 0,5Mio Daten aber das reicht anscheinend DFS-R um den Dienst zu verweigern. Ich werde mal versuchen am Wochenende mit Robocopy die Daten von Server A auf Server B zu kopieren in der Hoffnung, das DFS-R dann wieder auf die Beine kommt damit man das ganze endlich vernünftig angehen kann.
-
Leider nein. Beide Server laufen auf getrennten, unverwalteten Stand alone ESX Server ohne Vsphere und ohne Vmotion oder ohne Speicherreplikation. Ursprünglich war die Idee vor mind. 15 Jahren so, dass Auf Server A gearbeitet wird, die Freigaben via DFS-R auf Server B repliziert werden. Fullbackup wird dann auf Server B gefahren, weil dort keine Zugriffe/Änderungen sind. Heute sind es knapp 23TB und die Synchronisierung will nicht mehr richtig, weil die DFSR Datenbank wahrscheinlich zu groß ist. Mein Ansatz ist DFSR auf neue Volumes zu unterteilen, sodass nicht mehr als 4TB / Partition (& DFS Datenbank) Daten repliziert werden. Ein neues Konzept wäre natürlich besser aber es gibt derzeit kein Platz um die 23TB auszulagern oder zu puffern. Weiß jemand ob VSC mit DFSR zu vielen Problemen führt. VSC läuft leider auch 3x täglich auf dem großen DFSR Volume mit 23TB. ISt sicher nicht best practise aber die Strukturen sind so und ich muss erst eine Alternative haben bwvor ich die vielen verwöhnten User davon entwöhnen kann.