Tossi65
-
Gesamte Inhalte
68 -
Registriert seit
-
Letzter Besuch
Fortschritt von Tossi65
")





-
Über Replikation -> Distributor-> Datenbanken kannst du die Datenbank anhaken. Dann kannst du die Abos bzw. Verteiler konfigurieren
-
Danke an alle, habe das Problem gelöst.
-
Guten Morgen, nein. Ich suche Hilfe und Unterstützung. Ich dachte mir, wenn es eine Stored Procedure zum Entfernen der Replikationsobjekte einer Datenbank gibt, muss es auch eine zum hinzufügen geben. Das würde mir die Sache sehr vereinfachen. So könnte ich eine Datenbank zu einer bestehenden Replikation hinzufügen, wenn die Replikationsobjekte wieder drin sind. Natürlich muss ich Agenten usw. wieder manuell hinzufügen. Aber nur für diese Datenbank. Danke Torsten
-
Guten Morgen, ich habe folgende Frage: Ich möchte eine Datenbank, die repliziert wird. auf einen anderen SQL Server übertragen. Mit sp_restoredbreplication kann ich die bestehenden Replikation aus der Datenbank entfernen. Aber auf dem neuen SQL Server gibt es auch eine Replikation und dort will ich diese mit einbauen. Wie kann ich das machen, ohne die komplette Replikation für diesen SQL Server neu machen zu müssen. Wenn es eine Stored Proc zum entfernen gibt muss es doch eine zum hinzufügen geben? Gruß Torsten
-
SQL Server Transaktion Replikation
Tossi65 antwortete auf ein Thema von Tossi65 in: Windows Server Forum
Hallo NIls, ich weiß, diese Diskussion haben wir schon einmal geführt. Aber die Kunden an den Standorten wollen die Produktionsdaten vor Ort haben, für den Fall der Fälle. Internet kaputt. Wir haben uns schon SSIS angeschaut, aber diese Framework ist zu starr für unseren Bedürfnisse. Somit behalten wir unser altes System so lange es geht. Gruß Torsten -
SQL Server Transaktion Replikation
Tossi65 antwortete auf ein Thema von Tossi65 in: Windows Server Forum
Der Fehler lag an eine Publikation.. Diese hat ein SnapShot immer wieder im weiter nach einem Fehler neu gestartet und so die Platte vollgemüllt. Ich habe dies dann gelöscht und noch einmal neu aufgesetzt. Jetzt geht es. Danke -
SQL Server Transaktion Replikation
Tossi65 antwortete auf ein Thema von Tossi65 in: Windows Server Forum
Ja ich habe den Link sunny61 gesehen und geschaut. Aber bevor ich einen weiteren Berater hinzuziehen darf, muss ich erst die Obrigkeit fragen. Mein Plan ist. wenn es nichts konkretes gibt. die Replikation für FR neu zu machen. Aber es gefällt mir nicht. Zum Glück ist es noch nicht aktiv in der Produktion. Wenn es aktiv ist, kann ich nicht einfach neu aufsetzen, da beider Initialisierung die Zieltabellen geleert werden. Dann haben die Maschinen keine Daten :( Deshalb brauche ich einen lösbaren anderen Weg. Gruß Torsten -
SQL Server Transaktion Replikation
Tossi65 antwortete auf ein Thema von Tossi65 in: Windows Server Forum
@v-rtc Das kenne ich und hab es auch gemacht. Aber der Agent meldet keinen Fehler, sondern : "Message: There is not enough space on the disk.". Ich kann jetzt nicht einfach dahin gehen und Dateien dort löschen, ich weiß ja nicht was schon bearbeitet ist. Außderdem gibt es da noch die Einträge in den Replikationsdatenbanken. Gibt es Befehle um eine Replikation zurück zu setzen und neu starten? Danke Torsten PS: Es wäre schön, wenn beim Resetten der Replikation für diese Agenten, die Dateien von der Patte gelöscht werden. ;) -
SQL Server Transaktion Replikation
Tossi65 antwortete auf ein Thema von Tossi65 in: Windows Server Forum
Es gibt ca. 5 Publikationen auf dieser Datenbank und nur eine spielt verrückt. -
SQL Server Transaktion Replikation
Tossi65 antwortete auf ein Thema von Tossi65 in: Windows Server Forum
Guten Morgen , Microsoft sagt nichts. Und im Internet findet man nichts, was nicht der Standardprozedur entspricht. Ich habe mit einem MS zertifizierten Berater Berater Kontakt aufgenommen. Dieser konnte mir aber auch nur die Standardprozedur nennen. Diese helfen aber nicht. Anscheinend kennt sich hier in Deutschland keiner richtig mit der Replikation von MS aus. Eine 2. Platte würde die Symptome überbrücken aber nicht das Problem lösen. Danke Torsten. -
Hallo, wir setzten die SQL Server Replikation zum Verteilen von Daten auf verschiedenen Standorte ein. Die Replikation läuft, aber die Replikation eines Standortes hat die Festplatte voll geschrieben.. Wie kann ich das Rückgängig machen, das auch die dazu gehörenden Replikation-Commands aus den Datenbanken verschwinden? Ich will nicht die gesamte Replikation neu aufsetzen müssen, da es ca. 25 Publikationen sind. Es gibt doch so viele Prozeduren. Gruß Torsten
-
SQL Server Fehlermeldung bei Berechtigung für Tabellenfunktion
Tossi65 antwortete auf ein Thema von Tossi65 in: MS SQL Server Forum
Ich habe jetzt mal die Berechtigungen per Script gesetzt und es geht. Es scheint ein Fehler in der SSMS zu sein. Danke für eure Unterstützung -
SQL Server Fehlermeldung bei Berechtigung für Tabellenfunktion
Tossi65 antwortete auf ein Thema von Tossi65 in: MS SQL Server Forum
Das kann nicht sein. Der Fehler kommt auf 3 verschiedenen PC's mit unterschiedlichen SSMS. -
SQL Server Fehlermeldung bei Berechtigung für Tabellenfunktion
Tossi65 antwortete auf ein Thema von Tossi65 in: MS SQL Server Forum
Guten Morgen, SSMS Version 19.3 und 20.1. Sql-Server Version 2012 und 2022. Gemeint ist das Anlegen von Datenbankrollen über die Eigenschaften/Securables. Gruß Torsten
-
SQL Server Fehlermeldung bei Berechtigung für Tabellenfunktion
Tossi65 hat einem Thema erstellt in: MS SQL Server Forum
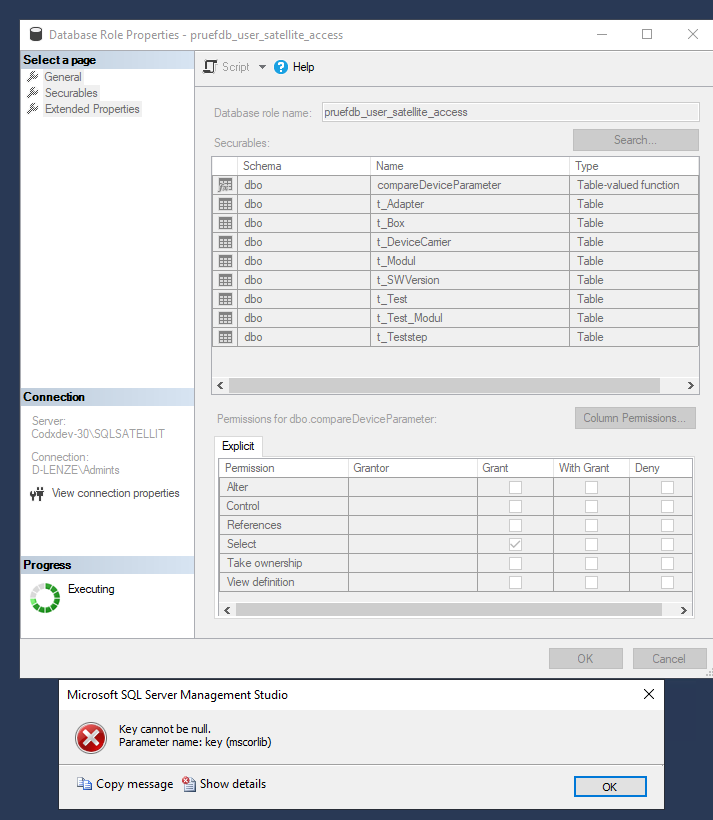
Hallo Kollegen, ich habe eine Datenbankrolle angelegt und will eine Tabellenfunktion berechtigen (Select). Aber wenn ich übernehmen sage, kommt folgender Fahler: Key cannot be null. Parameter name: key (mscorlib) im SQL Management Studio. Ich habe es Remote versucht oder direkt auf dem SQL Server. Nichts geht. Kennt jemand das Problem? Gruß Torsten